Este projeto visa desenvolver um sistema completo de análise de engajamento de conteúdos da Globo, aplicando progressivamente conceitos fundamentais de programação, desde lógica básica até banco de dados relacionais. O sistema é capaz de processar dados de interações de usuários com conteúdos em diferentes plataformas da Globo, identificando padrões de consumo e gerando relatórios analíticos.
Módulo: Lógica de Programação em Python
Objetivo: Aplicar conceitos fundamentais de programação Python para processar dados de engajamento.
Principais Implementações:
- Leitura e processamento de arquivo CSV com dados de interações
- Manipulação de strings, listas e dicionários
- Estruturas de controle (condicionais e laços)
- Funções para modularização do código
- Limpeza e transformação de dados
- Cálculo de métricas descritivas básicas
- Tratamento de exceções
Métricas Calculadas:
- Total de interações por conteúdo
- Contagem por tipo de interação
- Tempo total e médio de visualização
- Listagem de comentários por conteúdo
- Top-5 conteúdos mais visualizados
Módulo: Programação Orientada a Objetos
Objetivo: Refatorar o sistema aplicando princípios de POO para maior robustez e modularidade.
Classes Implementadas:
- Plataforma: Representa plataformas de consumo (Globoplay, G1, etc.)
- Conteudo: Classe base para conteúdos consumíveis
- Video: Herda de Conteudo, com cálculo de percentual assistido
- Podcast: Especialização para conteúdo de áudio
- Artigo: Especialização para conteúdo textual
- Interacao: Representa interações usuário-conteúdo
- Usuario: Gerencia dados e comportamentos dos usuários
- SistemaAnaliseEngajamento: Orquestra todo o sistema
Conceitos Aplicados:
- Encapsulamento com properties
- Herança e polimorfismo
- Métodos mágicos (str, repr, eq)
- Validação de dados nos construtores
- Organização em módulos e pacotes
Módulo: Algoritmos e Estruturas de Dados
Objetivo: Otimizar o processamento utilizando estruturas de dados eficientes e algoritmos de ordenação.
Estruturas Implementadas:
- Fila (Queue): Processamento sequencial das linhas do CSV (FIFO)
- Árvore de Busca Binária: Gerenciamento eficiente de conteúdos e usuários
- Operações: inserir, buscar, remover, percurso em ordem
- Complexidade: O(log n) em média para operações básicas
Algoritmos de Ordenação:
- Quick Sort: Ordenação geral para listas grandes
- Insertion Sort: Otimizado para listas pequenas
- Merge Sort: Alternativa híbrida eficiente
Análise de Complexidade:
- Documentação de complexidade temporal e espacial
- Notações Big-O, Big-Theta e Big-Ômega
- Otimização baseada no tamanho dos dados
Módulo: Banco de Dados
Objetivo: Evoluir para um sistema persistente utilizando MySQL, aplicando conceitos de modelagem relacional.
Implementações da Fase 4:
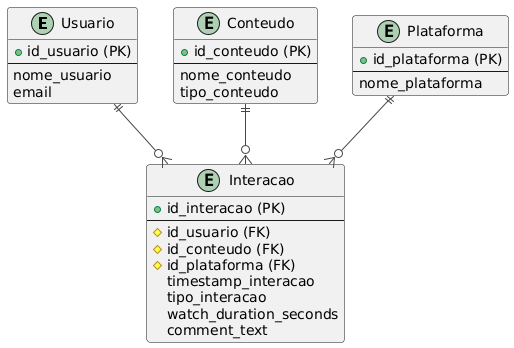
- Modelagem de Dados: MER e DER completos
- Schema SQL: Estrutura normalizada do banco de dados
- Carga de Dados: Script Python para importação do CSV
- Consultas SQL: Relatórios através de queries otimizadas
{kind=link}
- usuario: Dados dos usuários
- conteudo: Informações dos conteúdos
- plataforma: Plataformas de consumo
- tipo_interacao: Tipos de interação padronizados
- interacao: Registro de todas as interações
- conteudo_plataforma: Relação N:N entre conteúdos e plataformas
- Ranking de conteúdos mais consumidos - Ordenados por tempo total de consumo
- Usuários com maior tempo total de consumo - Soma do tempo em todas as interações
- Plataformas com maior engajamento - Total de likes, shares e comments
- Conteúdos mais comentados - Ranking por número de comentários
- Total de interações por tipo de conteúdo - Agrupamento por categoria
- Tempo médio de consumo por plataforma - Análise de comportamento por plataforma
- Quantidade de comentários por conteúdo - Detalhamento de feedback dos usuários
analise-engajamento-globo/
├── analise/ # Sistema de análise (Fases 2-3)
├── entidades/ # Classes do domínio (Fases 2-3)
├── estrutura_dados/ # Estruturas de dados (Fase 3)
├── ordenacao/ # Algoritmos de ordenação (Fase 3)
├── schema.sql # Script DDL do banco (Fase 4)
├── insercoes.sql # Dados iniciais (Fase 4)
├── carga_dados.py # Script de carga (Fase 4)
├── queries.sql # Consultas de relatórios (Fase 4)
├── mer.png # Diagrama MER (Fase 4)
├── README.md # Documentação
├── interacoes_globo.csv # Dados de entrada
└── main.py # Script principal
- Python 3.x - Linguagem principal
- MySQL - Banco de dados relacional
- CSV - Formato de dados de entrada
- PlantUML - Diagramação do MER
- Lógica de Programação: Estruturas de controle, funções, tratamento de exceções
- Programação Orientada a Objetos: Classes, herança, polimorfismo, encapsulamento
- Estruturas de Dados: Filas, árvores binárias de busca, análise de complexidade
- Algoritmos: Ordenação (Quick Sort, Insertion Sort, Merge Sort)
- Banco de Dados: Modelagem relacional, SQL (DDL, DML, DQL), normalização
Desenvolvido durante o curso Academia Globotech da Ada em parceria com a Globo, com 💛 por @mayasrl e equipe