Questa applicazione consente di prevedere la probabilità di presenza di una malattia cardiaca a partire da parametri clinici inseriti dal paziente.
Il progetto implementa un sistema predittivo per stimare il rischio cardiaco a partire da dati clinici inseriti da utente. L'app si basa su diversi algoritmi di classificazione, valutati tramite cross-validation e selezionati in base all'accuratezza. L’interfaccia permette di inserire i dati manualmente, inviarli al backend e ricevere la predizione, accompagnata da una stima di probabilità e un livello di rischio.
- Inserimento dati clinici tramite form (HTML/JS/CSS)
- Normalizzazione automatica delle feature
- Selezione del miglior modello predittivo
- Ottimizzazione dei parametri tramite GridSearch
- Previsione con probabilità
- Visualizzazione di grafici e statistiche
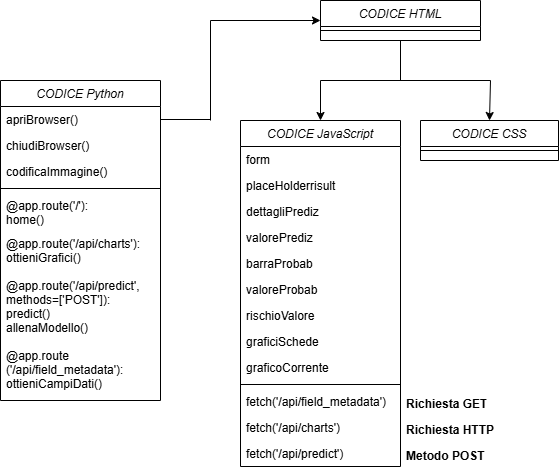
L’applicazione integra una parte frontend realizzata con HTML, JavaScript e CSS, e una parte backend sviluppata in Python integrando Flask. L'intero sistema è supportato da modelli di machine learning addestrati sui dati clinici.
Nella pagina principale dell’applicazione è presente un’interfaccia grafica formata da:
- Un form interattivo dove l’utente può inserire i propri dati clinici
- Una sezione dei risultati, che mostra l’esito della predizione (POSITIVO o NEGATIVO), la probabilità calcolata, e una valutazione del livello di rischio (BASSO, MODERATO o ALTO)
- Una sezione di grafici che mostrano la distribuzione dei dati e il comportamento del modello
Quando l’utente preme il pulsante “Predici”, i dati inseriti vengono raccolti in formato JSON e inviati a Python tramite Flask tramite una richiesta HTTP POST all'endpoint /api/predict
Il backend riceve i dati e li passa al modello predittivo addestrato in precedenza. I dati vengono convertiti in DataFrame con le stesse colonne del dataset originale, vengono normalizzati utilizzando lo stesso StandardScaler usato durante l’addestramento e vengono passati al modello ottimizzato, che restituisce:
- La classe predetta (0 = negativo, 1 = positivo)
- La probabilità associata In base alla probabilità, viene assegnato un livello di rischio:
- < 40% → BASSO
- 40–70% → MODERATO
- 70% → ALTO
Questi risultati vengono poi restituiti al frontend come risposta JSON.
Una volta ricevuta la risposta dal backend, l’interfaccia aggiorna:
- Il testo dell’esito: POSITIVO o NEGATIVO
- Una barra colorata rappresentante la probabilità
- Il valore numerico della probabilità (%)
- Il livello di rischio (con colore associato)
L’interfaccia include anche un bottone di “Reset” che:
- Cancella i dati inseriti
- Nasconde il risultato precedente
- Ripristina automaticamente i valori di default, richiamandoli dal backend
Durante la fase di sviluppo:
- Il dataset viene letto in pandas
- I dati vengono divisi in set di training e test (70%/30%) I modelli testati includono:
- Regressione Logistica
- KNN
- SVM
- Decision Tree
- Random Forest Il miglior modello viene selezionato in base all’accuratezza media. Viene poi ottimizzato usando GridSearchCV, provando diverse combinazioni di parametri per ogni modello. Una volta scelto il modello ottimale, esso viene salvato e utilizzato per le predizioni online degli utenti.
- Età (age)
- Sesso (sex)
- Tipo di dolore toracico (cp)
- Pressione arteriosa a riposo (trestbps)
- Colesterolo sierico (chol)
- Glicemia a digiuno > 120 mg/dl (fbs)
- Risultati dell'elettrocardiogramma a riposo (restecg)
- Frequenza cardiaca massima raggiunta (thalach)
- Angina indotta da esercizio fisico (exang)
- Vecchie anomalie ST (oldpeak)
- Pendenza del tratto ST (slope)
- Numero di vasi principali colorati con fluoroscopia (ca)
- Tipo di talassemia (thal)
L’app fornisce grafici statistici generati dal backend. Tra questi:
- Distribuzione dei casi positivi/negativi
- Importanza delle caratteristiche (feature importance) calcolata dal modello finale
- Grafici descrittivi delle variabili cliniche
- Confusion Matrix dell’ultimo modello ottimizzato Questi grafici vengono salvati come immagini e caricati dinamicamente nell'interfaccia. È possibile passare da un grafico all'altro tramite tab interattivi.
/api/field_metadata /api/charts/api/predictPer installare le librerie
pip install -r requirements.txtIn seguito, avviare l'applicazione herta.py
python herta.pyReadme realizzato con (https://readme.so)