Bu proje, Trabzon Üniversitesi Yapay Zeka ve Robotik Kulübü tarafından Ünides Programı kapsamında verdiğim eğitimde geliştirilmiştir.
Amaç, Türkçe belgeler üzerinde çalışan bir Retrieval-Augmented Generation (RAG) tabanlı soru-cevap sistemini kurmak ve öğretmektir.
Python 3.8+ ve şu kütüphaneler gereklidir:
pip install langchain langchain_community langchain_google_genai datasets faiss-cpu google-generativeaiGoogle Generative AI API anahtarınızı alıp tanımlayın:
export GOOGLE_API_KEY="senin_google_api_anahtarın"
export GOOGLE_LLM="gemini-1.5-pro-latest" # OpsiyonelProje dosyasının olduğu dizinde:
python dosya_adı.pyİlk çalıştırmada sistem faiss_index/ dizinini oluşturur ve belgeleri ekler.
Sonraki çalıştırmalarda dizin doğrudan yüklenir.
Kullanım örneği:
>>> Türkiye'nin başkenti neresidir?
[Cevap]
Ankara.
[Kaynak Parçalar]
1. Türkiye'nin başkenti Ankara'dır ve 1923 yılında başkent ilan edilmiştir...
Çıkmak için: boş satır girin veya Ctrl + C / Ctrl + D.
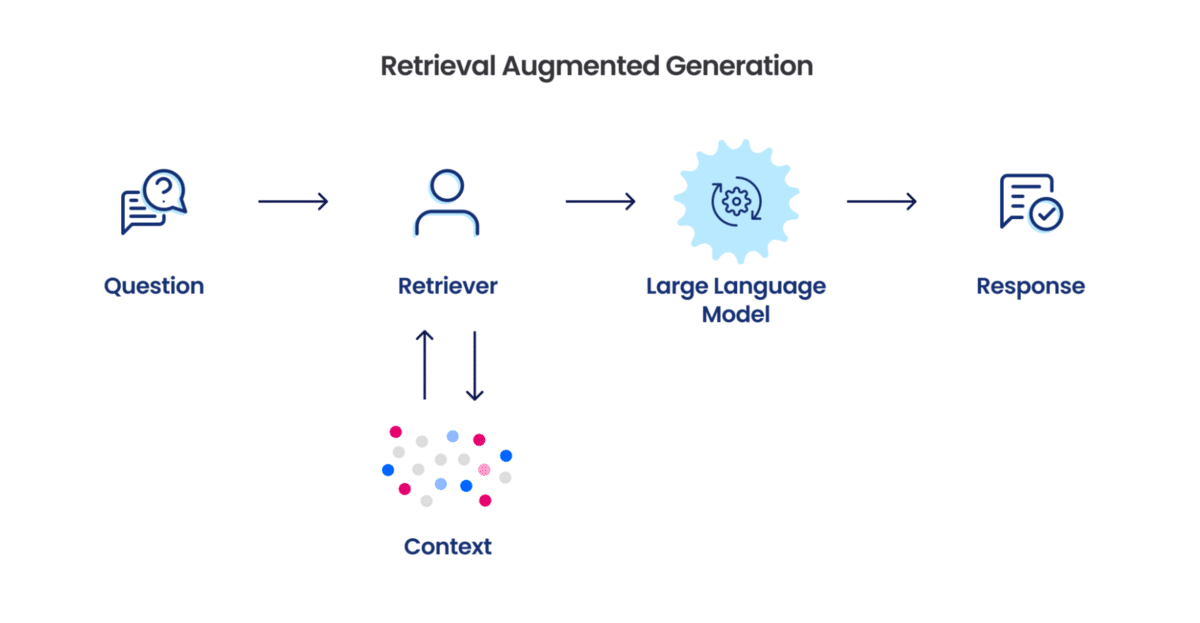
RAG, bir yapay zekanın yalnızca ezber bilgisini değil, dış belgeleri arayıp bunlarla yanıt üretmesini sağlayan sistemdir.
1️⃣ Soru anlam vektörüne dönüştürülür. 2️⃣ FAISS dizininden en yakın belgeler çekilir. 3️⃣ Yanıt sadece bu belgelerle üretilir. 4️⃣ Bağlam yoksa “Bilmiyorum” yanıtı verilir.
✅ Güncel ve doğru kaynaklardan yanıt verir. ✅ Eğitim verisinde olmayan sorulara doğru yanıt verir. ✅ Halüsinasyon riski azalır. ✅ Belgeler değiştikçe sistem güncellenir.
| Bileşen | Açıklama |
|---|---|
| Soru vektörü | Sorunun anlamını sayısal olarak temsil eder. |
| FAISS dizini | Belgelerin anlam vektörlerini saklar ve arama yapar. |
| Retriever | En alakalı belgeleri bulur. |
| Yanıt üretici | Sadece bulunan belgelerle yanıt üretir. |
- Kullanılan veri kümesi:
Metin/WikiRAG-TR. - Yanıtlar sadece belgelerden gelen bilgiye dayanır, model uydurma yapmaz.Eğitim amamçlı tasarlanmıştır.Bu yüzden tam anlamıyla doğru çalışan bir model değildir.
- Sistem Türkçe sorular için tasarlanmıştır.