







bibtex-autocomplete or btac is a simple script to autocomplete BibTeX bibliographies. It reads a BibTeX file and looks online for any additional data to add to each entry. It can quickly generate entries from minimal data (a lone title is often sufficient to generate a full entry). You can also use it to only add specific fields (like DOIs, or ISSN) to a manually curated bib file.
It is designed to be as simple to use as possible: just give it a bib file and let btac work its magic! It combines multiple sources and runs consistency and normalization checks on the added fields (only adds URLs that lead to a valid webpage, DOIs that exist at https://dx.doi.org/, ISSN/ISBN with valid check digits...).
It attempts to complete a BibTeX file by querying the following domains:
- openalex.org: ~240 million entries
- www.crossref.org: ~150 million entries
- arxiv.org: open access archive, ~2.4 million entries
- semanticscholar.org: ~215 million entries
- unpaywall.org: database of open access articles, ~48 million entries
- dblp.org: computer science, ~7 million entries
- researchr.org: computer science
- inspirehep.net: high-energy physics, ~1.5 million entries
Big thanks to all of them for allowing open, easy and well-documented access to their databases. This project wouldn't be possible without them. You can easily narrow down the list of sources if some aren't relevant using command line options.
- Demo
- Quick overview
- Installation
- Usage
- Command line arguments
- Running from python
- Credit and license

How does it find matches?
btac queries the websites using the entry DOI (if known) or its title. So
entries that don't have one of those two fields will not be completed.
- DOIs are only used if they can be recognized, so the
doifield should contain "10.xxxx/yyyy" or an URL ending with it. - Titles should be the full title. They are compared excluding case and punctuation, but titles with missing words will not match.
- If one or more authors are present, entries with no common authors will not
match. Authors are compared using lower case last names only. Be sure to use
one of the correct BibTeX formats for the author field:
(see https://www.bibtex.com/f/author-field/ for full details)
author = {First Last and Last, First and First von Last} - If the year is known, entries with different years will also not match.
Disclaimers:
-
There is no guarantee that the script will find matches for your entries, or that the websites will have any data to add to your entries, (or even that the website data is correct).
-
The script is designed to minimize the chance of false positives - that is adding data from another similar-ish entry to your entry. If you find any such false positive please report them using the issue tracker.
How are entries completed?
Once responses from all websites have been found, the script will add fields by performing a majority vote among the sources. To do so it uses smart normalization and merging tactics for each field:
- Authors (and editors) match if they have same last names and, if both first names present, the first name of one is equal/an abbreviation of the other. Author lists match they have at least one author in common.
- ISSN and ISBN are normalized and have their check digits verified. ISBN are converted to their 13 digit representation.
- URL and DOI are checked for valid format, and further validated by querying them online to ensure they exist. DOI are normalized to strip any leading URL and converted to lowercase.
- Many fields match with abbreviation detection (journal, institution, booktitle,
organization, publisher, school and series). So
ACMwill matchAssociation for Computer Machinery. - Pages are normalized to use
--as separator. - All other fields are compared excluding case and punctuation.
The script will not overwrite any user given non-empty fields, unless the
-f/--force-overwrite flag is given. If you want to check what fields are
added, you can use -v/--verbose to have them printed to standard output (with
source information), or -p/--prefix to have the new fields be prefixed with
BTAC in the output file.
Can be installed with pip :
pip install bibtexautocompleteYou should now be able to run the script using either command:
btac --version
python3 -m bibtexautocomplete --versionNote: pip no longer allows installing scripts globally in systems with other
package managers (like most Linux distros). You can install the script locally in
a virtual environment or globally
using pipx:
sudo apt install pipx
pipx install bibtexautocompleteIf you want tab based completion for btac in your shell, you must install
the optional argcomplete dependency.
# Either install the package separately
pip install argcomplete
# Or as a btac optional dependency
pip install bibtexautocomplete[tab]You then need to register the tab auto-completer. On bash/zsh:
- You can activate completion just for this script with
For repeated use, I recommend adding this line to your
eval "$(register-python-argcomplete btac)"
.bashrcor.bash_profile. - Alternatively, you can activate completion for all python scripts
using argcomplete by running
and then restarting your shell
activate-global-python-argcomplete
If using another shell than bash/zsh on Linux or MacOS, support is not guaranteed. See github.com/kislyuk/argcomplete/contrib for instructions on getting it working on other shells.
This package has two dependencies (automatically installed by pip) :
- bibtexparser (<2.0.0)
- alive_progress (>= 3.0.0) for the fancy progress bar
It also has an optional dependency, argcomplete for tab based completion. It is installed if you pip install bibtexautocomplete[tab].
The command line tool can be used as follows:
btac [--flags] <input_files>Examples :
btac my/db.bib: reads from./my/db.bib, writes to./my/db.btac.bib. A different output file can be specified with-o.btac -i db.bib: reads fromdb.biband overwrites it (inplace flag). Avoid on non backed-up/version-controlled files, I'd hate it if my script corrupted your data.btac folder: reads from all files ending with.bibin folder. Excludes.btac.bibfiles unless they are the only.bibfiles present. Writes tofolder/file.btac.bibunless inplace flag is set.btacwith no inputs is same asbtac ., reads file from current working directorybtac -c doi ...only completes DOI fields, leave others unchangedbtac -v ...verbose mode, pretty prints all new fields when done. See this image for a preview of verbose output.
Note: the parser doesn't preserve format information, so this script will reformat your files. Some formatting options are provided to control output format.
Slow responses: Sometimes due to server traffic, a source DB may take significantly longer
to respond and slow btac.
- You can increase timeout with
btac ... -t 60(60s) orbtac ... -t -1(no timeout) - You can disable queries to the offender
btac ... -Q <website> - You can try again at another time
As btac has a lot of option I'd recommend setting up an alias if you use a lot
regularly.
-
-o --output <file.bib>Write output to given file. Can be used multiple times when also giving multiple inputs. Maps inputs to outputs in order. If there are extra inputs, uses default name (
old_name.btac.bib). Ignored in inplace (-i) mode.For example
btac db1.bib db2.bib db3.bib -o out1.bib -o out2.bibreadsdb1.bib,db2.bibanddb3.bib, and write their outputs toout1.bib,out2.bibanddb3.btac.bibrespectively. -
-i --inplaceModify input files inplace, ignores any specified output files. Avoid on non backed-up/version-controlled files, I'd hate it if my script corrupted your data. -
-O --no-outputdon't write any output files (except the one specified by--dump-data) can be used with-v/--verbosemode to only print a list of changes to the terminal
-
-q --only-query <site>or-Q --dont-query <site>Restrict which websites to query from.
<site>must be one of:openalex,crossref,arxiv,s2,unpaywall,dblp,researchr,hep. These arguments can be used multiple times, for example to only query Crossref and DBLP use-q crossref -q dblpor-Q openalex -Q researchr -Q unpaywall -Q arxiv -Q s2 -Q hep -
-e --only-entry <id>or-E --exclude-entry <id>Restrict which entries should be autocompleted.
<id>is the entry ID used in your BibTeX file (e.g.@inproceedings{<id> ... }). These arguments can also be used multiple times to select only/exclude multiple entries -
--sf --start-from <id>Only complete the entries that come after the given id (inclusive). This is useful when resuming a previously interrupted auto-completion on the same file.
-
-c --only-complete <field>or-C --dont-complete <field>Restrict which fields you wish to autocomplete. Field is a BibTeX field (e.g.
author,doi,...). So if you only wish to add missing DOIs use-c doi. -
-b --filter-fields-by-entrytype <required|optional|all>only add fields that correspond to the given entry type in bibtex's data model. Disabled by default.requiredonly adds required fields,optionaladds required and optional fields, andalladds required, optional and non-standard fields (doi, issn and isbn). A list of required/optional fields by entry type can be found on the tex stackexchange -
-w --overwrite <field>or-W --dont-overwrite <field>Force overwriting of the selected fields. If using
-W author -W journalyour force overwrite of all fields exceptauthorandjournal. The default is to override nothing (only complete absent and blank fields).For a more complex example
btac -C doi -w authormeans complete all fields save DOI, and only overwrite author fields.You can also use the
-fflag to overwrite everything or the-pflag to add a prefix to new fields, thus avoiding overwrites. -
-m --markand-M --ignore-markThis is useful to avoid repeated queries if you want to run
btacmany times on the same (large) file.By default,
btacignores any entry with aBTACqueriedfield.--ignore-markoverrides this behavior.When
--markis set,btacadds aBTACqueried = {yyyy-mm-dd}field to each entry it queries.
You can use the following arguments to control how btac formats the new fields
--fu --escape-unicodereplace unicode symbols by latex escapes sequence (for example: replaceéwith{\'e}). The default is to keep unicode symbols as is.--fp --protect-uppercase <field>or--FP --dont-protect-uppercase <field>or--fpa --protect-all-uppercase, insert braces around words containing uppercase letters in the given fields to ensure bibtex will preserve them. The three arguments are mutually exclusive, and the first two can be used multiple times to select/deselect multiple fields.
Unfortunately bibtexparser doesn't preserve format information, so this script will reformat your BibTeX file. Here are a few options you can use to control the output format:
-
--fa --align-valuespad field names to align all values@article{Example, author = {Someone}, doi = {10.xxxx/yyyyy}, }
-
--fc --comma-firstuse comma first syntax@article{Example , author = {Someone} , doi = {10.xxxx/yyyyy} , }
-
--fl --no-trailing-commadon't add the last trailing comma -
--fi --indent <space>space used for indentation, default is a tab. Can be specified as a number (number of spaces) or a string with spaces and_,t, andncharacters to mark space, tabs and newlines.
-
-p --prefixWrite new fields with a prefix. The script will addBTACtitle = ...instead oftitle = ...in the bib file. This can be combined with-fto safely show info for already present fields.Note that this can overwrite existing fields starting with
BTACxxxx, even without the-foption. -
-f --force-overwriteOverwrite already present fields. The default is to overwrite a field only if it is empty or absent -
-D --diffonly print the new fields in the output file. In this mode, old fields are removed and entries with no new fields are deleted. This cannot be used with the-i --inplaceflag for safety reasons. If you really want to overwrite your input file (and delete a bunch of data in the process), you can do so with by specifying it explicitly via the-o --outputoption. -
-u --copy-doi-to-urlIf a DOI is found but no URL, set the URL field tohttps://dx.doi.org/<doi> -
-t --timeout <float>set timeout on request in seconds, default: 20.0 s, increase this if you are getting a lot of timeouts. Set it to -1 for no timeout. -
-S --ignore-sslbypass SSL verification. Use this if you encounter the error:[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: certificate has expired (_ssl.c:1129)Another (better) fix for this is to run
pip install --upgrade certifito update python's certificates. -
--ns --no-skipdisable skipping. By default, btac will skip queries to sources if they lag behind (>=10 queries remain or >=60s delay between queries) when 2/3rds of the other sources have completed. This avoids having a single source slow down btac considerably. -
-d --dump-data <file.json>writes matching entries to the given JSON files.This allows to see duplicate fields from different sources that are otherwise overwritten when merged into a single entry.
The JSON file will have the following structure:
[ { "entry": "<entry_id>", "new-fields": 8, "crossref": { "query-url": "https://api.crossref.org/...", "query-response-time": 0.556, "query-response-status": 200, "author" : "Lastname, Firstnames and Lastname, Firstnames ...", "title" : "super interesting article!", "..." : "..." }, "openalex": ..., "arxiv": null, // null when no match found "unpaywall": ..., "dblp": ..., "researchr": ..., "inspire": ... }, ... ] -
-v --verboseverbose mode shows more info. It details entries as they are being processed and shows a summary of new fields and their source at the end. Using it more than once prints debug info (up to four times).Verbose mode looks like this:
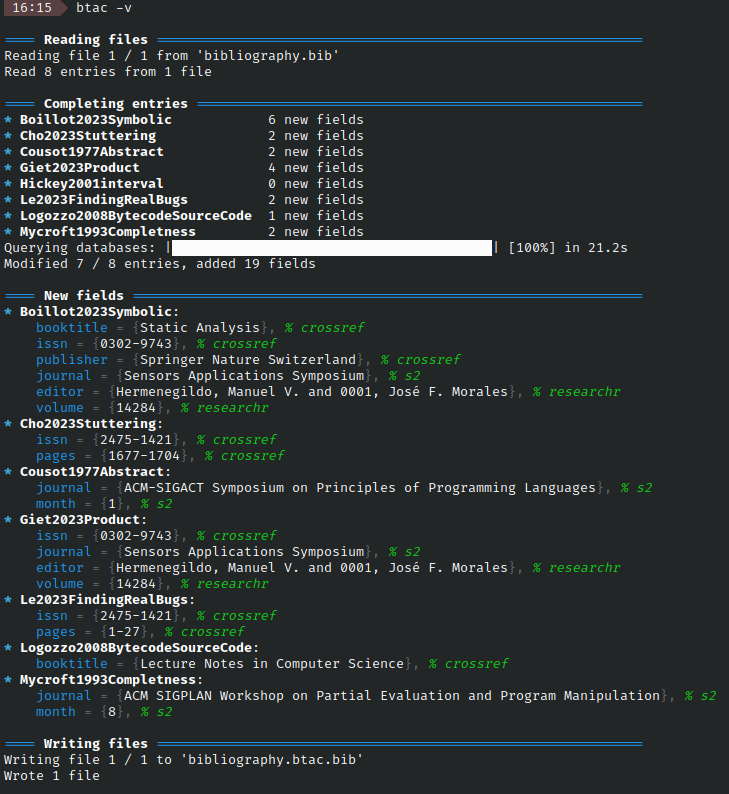
-
-s --silenthide info and progress bar. Keep showing warnings and errors. Use twice to also hide warnings, thrice to also hide errors and four times to also hide critical errors, effectively killing all output. -
--color <auto|always|never>sets whether btac should use colored output. Can also be set by theNO_COLORor theCLICOLOR_FORCEenvironment variables, as explained here: http://bixense.com/clicolors/. Defaults toauto, which checks if standard output is a terminal via theisattyfunction -
--versionshow version number -
-h --helpshow help
You can call the main function of this script from python directly, specifying a list of arguments as you would on the command line:
from bibtexautocomplete import main
main(["file.bib", "-o", "output.bib"])For more interactivity and more varied inputs/outputs than reading from files and
writing to files, use the BibtexAutocomplete class. Here is a small demonstration:
from bibtexautocomplete import BibtexAutocomplete
# 1 - Create a BibtexAutocomplete instance with the desired settings
# Note: some settings are stored in global variables, so avoid having multiple
# instances of this class in parrallel
completer = BibtexAutocomplete(**settings)
# 2 - Load a Bibtex information using any of the following
# 2.1 - Load a single file or list of files
completer.load_file("ex.bib")
completer.load_file(["ex1.bib", "ex2.bib"])
# 2.2 - Load bibtex content as string or list of strings
completer.load_string(bibtex)
completer.load_string([bibtex1, bibtex2])
# 2.3 - Load entry, list of entries, or list of list of entries as a dict
# Lowercase name for fields, "ID" and "ENTRYTYPE" for entry id and type
completer.load_entry({
"author": "John Doe",
"title": "My Awesome Paper",
"ID": "foo",
"ENTRYTYPE": "article"
})
# You can also specify author and editor fields as a (list of) firstnames and lastnames
completer.load_entry({
"author": [{"firstname": "John"}, {"lastname": "Doe"}],
"title": "My Awesome Paper",
"ID": "foo",
"ENTRYTYPE": "article"
})
# 3 - Run the completer (may take a while)
completer.autocomplete()
# 4 - Get the results
# As the input may be split into mutliple files (or strings), so is the output
# The length of output list is the sum of:
# - the length of lists passed to load_file and load_string
# - the number of calls to load_entry
# When using write_file, you must provide the same number of filepaths
completer.write_file("ex.btac.bib")
completer.write_file(["ex1.bib", "ex2.bib"])
completer.write_string() # type: list[str]
completer.write_entry() # type: list[list[EntryType]]The settings passed to the BibtexAutocomplete constructor mirror the
command-line arguments, see their documentation for
details.
lookups: Iterable[LookupType] = ...,
# Specify which entries should be completed (default: all)
entries: Optional[Container[str]] = None,
mark: bool = False,
ignore_mark: bool = False,
prefix: bool = False,
escape_unicode: bool = False,
diff_mode: bool = False,
# Restrict which fields should be completed (default: all)
fields_to_complete: Optional[Set[FieldType]] = None,
# Specify which fields should be overwritten (default: none)
fields_to_overwrite: Optional[Set[FieldType]] = None,
# Specify which fields should have uppercase protection (default: none)
fields_to_protect_uppercase: Container[str] = set(),
filter_by_entrytype: Literal["no", "required", "optional", "all"] = "no",
copy_doi_to_url: bool = False,
start_from: Optional[str] = None,
dont_skip_slow_queries: bool = False,
timeout: Optional[float] = 20, # Timeout on all queries, in seconds
ignore_ssl: bool = False, # Bypass SSL verification
verbose: int = 0, # Verbosity level, from 4 (very verbose debug) to -3 (no output)
# Output formatting
align_values: bool = False,
comma_first: bool = False,
no_trailing_comma: bool = False,
indent: str = "\t",This project was first inspired by the solution provided by thando in this TeX stack exchange post. I worked on as part of a course on Web data management in 2021-2022 as part of my masters (MPRI).
This project is free and open-source. It is distributed under terms of the MIT License. See the LICENSE file for more information