Conversation
|
using KVM/NFS, I tested this scenario:
basically different results than reported by @GabrielBrascher . this is with @GabrielBrascher 's fix in this PR. |
...e/snapshot/src/main/java/org/apache/cloudstack/storage/snapshot/DefaultSnapshotStrategy.java
Outdated
Show resolved
Hide resolved
|
Not good (still testing a few more scenarios and will update this comment once done): XENSERVER (7.1) + NFSsnapshot.backup.to.secondary = TRUE (default)MANUAL SNAPS: LGTM
SCHEDULED SNAPS: MAYBE OK - someone should advise
snapshot.backup.to.secondary = FALSEMANUAL SNAPS: LGTM SCHEDULED SNAPS: KVM (CENT7.1) + NFSsnapshot.backup.to.secondary TRUE (default)MANUAL SNAPS: LGTM
SCHEDULED SNAPS:
snapshot.backup.to.secondary = FALSEMANUAL SNAPS: BROKEN
SCHEDULED SNAPS: NA
VMware not tested,but will re-test that it's NOT affected once we have everything else fixed. |
|
@andrijapanicsb thanks for all the tests, I am going to check this issue. |
|
@andrijapanicsb thank you very much for all the tests. Here follows an update on I have been testing this implementation (tested with 4.13.1 and also on a port to 4.14.0). The snapshotting with Environment:
Can you please share more details on the issue that you had? Are there exceptions on management or the agent node? Is the DB being correctly updated (snapshots, volumes, snapshot_store_ref)? Note that snapshots on NFS as primary storage is a bit different than on secondary. The snapshot handling for NFS (primary) is executed with the help of the managesnapshot.sh script. That script on KVM + NFS (primary) creates a lvm, which makes a bit tricky to find the snapshot volume compared to other approaches (e.g. ceph: Basically the script runs a lvm lvcreate: Thus, the snapshot path will become something as Is that happening on your test environment? |
|
@GabrielBrascher That is happening in our environment. However, when I create a first snapshot of a data volume, it also makes a copy in the secondary storage. Successive snapshots do not get created in the secondary storage but when I try to restore them or create a new volume from them it fails, while I can only use the first snapshot that I had created to create a new volume / restore the snapshot. |
|
Got it @davidjumani, thanks for the feedback. |
|
So - yes, when using KVM+NFS and snapshot.backup.to.secondary=false - there is all kind of mess with snapshots happening - both in 4.11.3 and in master - which implies lack of proper code implementation for this combo. The rest looks good and I'm tempted to give this specific PR a LGTM (after some more testing of what was already tested before as good) |
|
I proposed that we continue/merge this PR as it is (I want to confirm a few more things with testing, specifically that VMware is still not affected) and close the "garbage" problem as it seems solved. For the KVM+NFS/local very bad behaviour when snapshot.backup.to.secondary=false - that is traced back to the original implementation, which seems only done for KVM + CEPH, and so I propose that we simply change the description of this global settinh to ... Applicable only for KVM = Ceph" @GabrielBrascher sounds ok to you? |
|
@andrijapanicsb sounds good to me, considering the raised context and all tests done so far. Let's run a few more tests then. |
| if (isSnapshotOnPrimaryStorage(snapshotId) && snapshotSvr.deleteSnapshot(snapshotOnPrimaryInfo)) { | ||
| snapshotOnPrimary.setState(State.Destroyed); | ||
| snapshotStoreDao.update(snapshotOnPrimary.getId(), snapshotOnPrimary); | ||
| snapshotDao.remove(snapshotId); |
There was a problem hiding this comment.
Perhaps this is leading to the record having a removed date on the snapshots table which later on causes issues during GC ?
There was a problem hiding this comment.
That looks like the issue indeed, I will take a second look at this.
@andrijapanicsb could you double-check the code? When i manually check 4.13, i don't see the lines added in the screenshot below from #3194 . |
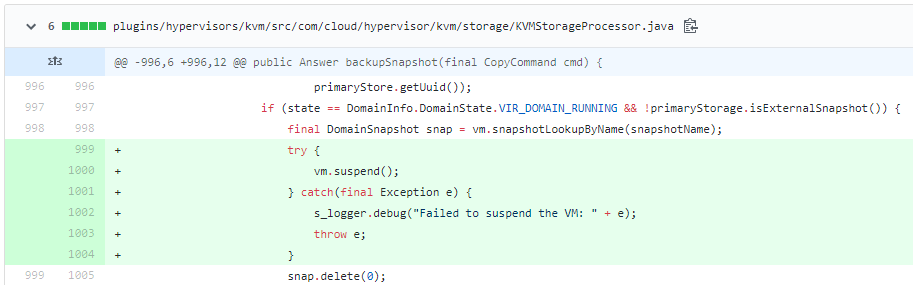
|
@Slair1 I can't, I'm off as from 10min ago (late night, time for beer) - perhaps @DaanHoogland can confirm once more tomorrow.... |
|
Is this for volume or VM snapshots @Slair1 ? - as volume snapshots are NOT possible for KVM while the VM is running (someone thought that's interesting to do that, due to qcow2 safety...so now it's useless for KVM...) |
It is for volume snapshots, but you're correct the global setting kvm.snapshot.enabled needs to be enabled. But this brings up another point, we are wondering if we need to do a suspend before deleting VM Snapshots also. From our examination of the code, it looks like both VM Snapshots and Volume Snapshots use the java libvirt libraries to take and delete the snapshot... so I would think they could both have the same corruption issue if the snapshot is deleted while the VM is powered-on and not suspended during the snapshot delete... |
|
Trillian test result (tid-1401)
|
|
@blueorangutan test centos7 xenserver-71 |
|
@andrijapanicsb a Trillian-Jenkins test job (centos7 mgmt + xenserver-71) has been kicked to run smoke tests |
|
@blueorangutan test |
|
@andrijapanicsb a Trillian-Jenkins test job (centos7 mgmt + kvm-centos7) has been kicked to run smoke tests |
|
Trillian test result (tid-1403)
|
|
Trillian test result (tid-1404)
|
|
those were spurious failures obviously, @andrijapanicsb as they passed after applying insanity. If you manual verification checks out we should merge and release. |
There was a problem hiding this comment.
LGTM from my side:
- 3 x LGTMs (2 x Approvals), test matrix (KVM,VMware,XS) runs fine (known privategtw test issues, fixed in master)
- Manual tests fine (with some outstanding fix/refactoring work to be done via issue #4018
Will update the PR description to explain what HAS and HAS NOT been fixed.
Merging.
@andrijapanicsb just wanted to ping you on this again thanks! |
|
I don't see it myself, despite @DaanHoogland confirming the commit being present in 4.13 branch... Some regression by someone? |
|
but you can test 4.13.1 RC1 and see if VMs are suspended as expected - perhaps some parts of the code were refractored or so... |
@andrijapanicsb @DaanHoogland from our testing it is just gone... so strange - i hope other commits didn't get dropped somehow. I even checked the "blame" and I don't see a refactor - the last change in branch 4.13 was 4-years ago for the section of code. |
|
Agree, it's gone/messed up (trying to understand what happened with some of my colleagues who are good with git) - some code refactoring happened between from 4.11 to 4.12, and it seems gone during this... (from 4.12 and onwards) - so it's NOT new issue (that code missing) |
|
@Slair1 do you mind creating a PR for MASTER (not 4.13 - we already have RC1 for vote today) to add back those few lines... it's incredible - the global desc that the VM will be suspended is STILL there in 4.12/4.13/master, but the "vm.suspend" code is |
|
@Slair1 - the bug you shared (RHEL bug), was marked as WON'T FIX - and was raised against qemu-kvm-0.12.1.2-2.355.el6_4.1.x86_64 Can you please describe in which env (versions of qemu) you are seeing the corruption (as master/4.14 does NOT even support centos6) I would like to first REPRODUCE this issue on centos7+ instead of just suspending the VM (now that we think to AGAIN introduce the suspend thing) |
Thanks @andrijapanicsb . We have always been on CentOS7 - never 6. We have had many corrupt VMs from using the scheduled volume snapshot functionality... We had to turn off the ability to do volume snapshots while a VM is powered-on... We also stopped using VM Snapshots since the Delete VM Snapshot functionality deletes snapshots the same way as volume snapshots are deleted from the qcow2 files (after the snap is backed up to secondary storage). We are hoping the pause VM, delete snapshot, resume VM fixes this - we are still testing |
|
Clear, I did a bit of reading myself. Say, what about corruption when creating snapshots? - in recent qemu releases (2.10) qemu-img actually opens qcow2 with read-write access instead of read-only previously (don't ask me why, documented behavior). This would probably mean that even backing up the snap to Secondary Storage (with qemu 2.10) will not work (requires a use of --force-share flag, which we don't have implemented in ACS) unless the VM is suspended - did you have a change to test qemu 2.10 (that is separate Centos SIG repo), etc? What about corruption while creating snapshots with stock qemu version 1.53? |
|
tested, confirmed the issue with latest centos7 host (centos5.5 ext3 guest - simulated high IO load while deleting the snap and broke the VM) Raised PR (for master only) #4029 EDIT: well, I "broke" the image (qemu-img check showing thousands of errors) but not the EXT3 inside the VM - EXT3 can't be broken as it seems (retrying testing with centos7 and the famous XFS which has the tendency to self-crash for fun...) |
|
@DaanHoogland @GabrielBrascher @andrijapanicsb @rhtyd Found an issue with this commit. Below are the steps to reproduce
I have made a fix so that it checks if the vm snapshot from which the snapshot is created, still exists on primary storage or not. If it exists then its not deleted from primary but only from secondary |
|
@ravening for which hypervisor is this? |
@andrijapanicsb This is for KVM The VM snpashot is not yet deleted. Ofcourse if VM snapshot is deleted then we should clean up the garbage. |
Description
copy of PR #3649 on a joint account for easier cooperation.
Tested both cases:
Note: @GabrielBrascher changed the name of the strategy from XenserverSnapshotStrategy to DefaultSnapshotStrategy due to the fact that the "Xenserver" strategy handles also Ceph, KVM, and do return
StrategyPriority.DEFAULTin any case except REVERT.Fixes: #3646
Types of changes
WHAT HAS BEEN FIXED / WORKs FINE:
-- snapshot.backup.to.secondary=FALSE - works (by design) only with KVM+Ceph - no garbage on Secondary/Primary storage 👍
--- snapshot.backup.to.secondary=FALSE does NOT work (by design) with other hypervisors/storage combo - so don't bother trying 😄
WHAT HAS NOT BEEN FIXED (tracked via #4018 ):