Retrieval-based Arabic Rating ChatBot for my Smart Methods training. Using NLTK, Keras and TKinter
- Spyder IDE (the arabic text is normal in anaconda applications, else you'll have to use the arabic reshaper)
- Miniconda
- keras
- nltk
- python 3.7 (or less)
conda create -n p37env python=3.7 (Create a virtual environment with this version or less)
conda activate p37env
conda install keras
conda install 'h5py==2.10.0' (downgrade h5py to avoid errors)
cd (to the folder you have your python file in)
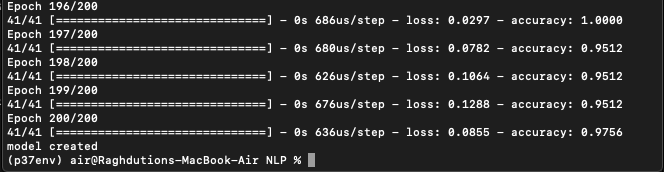
python train_chatbot.py
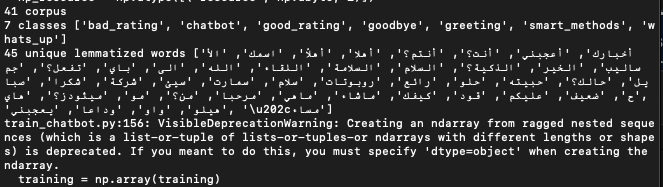
You'll get this:
# Fitting and saving the model
hist = model.fit(np.array(train_x), np.array(train_y), epochs=200, batch_size=5, verbose=1)
#here we specified the number of epochs to be 200
from nltk.stem.isri import ISRIStemmer #arabic stemmer
st = ISRIStemmer()
w= 'حركات'
m='يفعلون'
print("\t \t",st.stem(w)," \n")
print("\t \t",st.stem(m)," \n")
isri_stemmer = ISRIStemmer()
stem_word = isri_stemmer.stem("فسميتموها")
print("\t\t\t\t\t\t\t",stem_word)
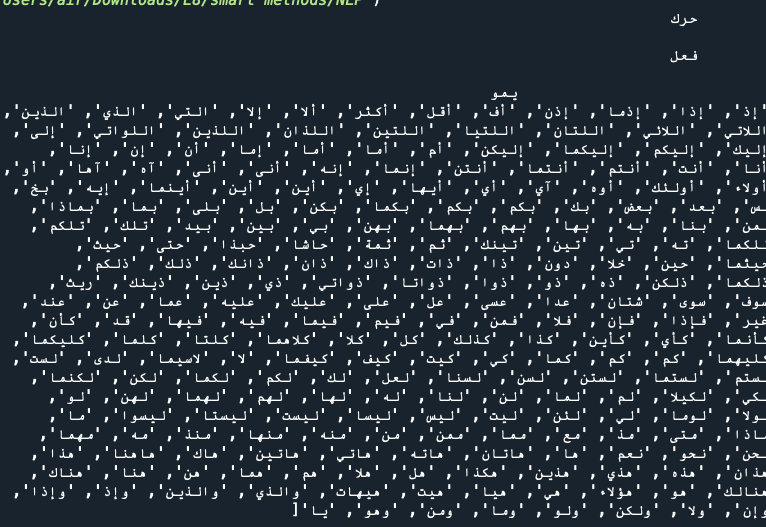
from nltk.corpus import stopwords
all_stopwords = stopwords.words('arabic')
print(all_stopwords)
Now run the GUI for Pythin (Tinkter)
python GUI_ChatBot.py
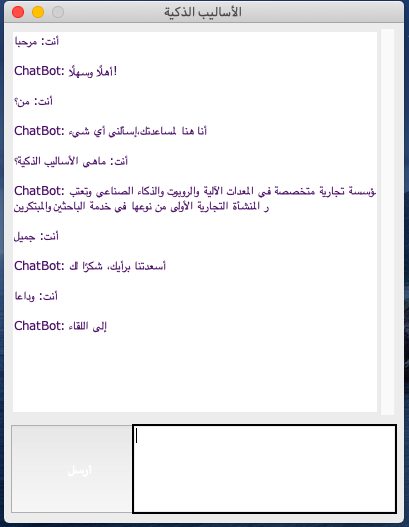
- Unfortantley, when I ran the codes I made for cleaning Arabic text, the accuracy went way down, and the ChatBot responses didn't make any sense. So, I removed them and only kept a few lines so the accuracy would rise back again to 0.9
if w in Arabic_stop_words:
words.remove(w)
# Normalize alef variants to 'ا'
nw = normalize_alef_ar(w)
# Normalize alef maksura 'ى' to yeh 'ي'
nw = normalize_alef_maksura_ar(w)
# Normalize teh marbuta 'ة' to heh 'ه'
nw = normalize_teh_marbuta_ar(w)
# removing Arabic diacritical marks
nw = dediac_ar(w)
words.extend(nw)
- keras wasn't compatible with python3.8, and this caused lot of erros and thats why I had to create a virtual environemnt with lower version than I use: Python3.8