- Gradient-free optimization of neural network parameters
-
Example:
f(x) = x^2(loss = log10(MSE(y_predict, x**2))) -
Genetic algorithm:
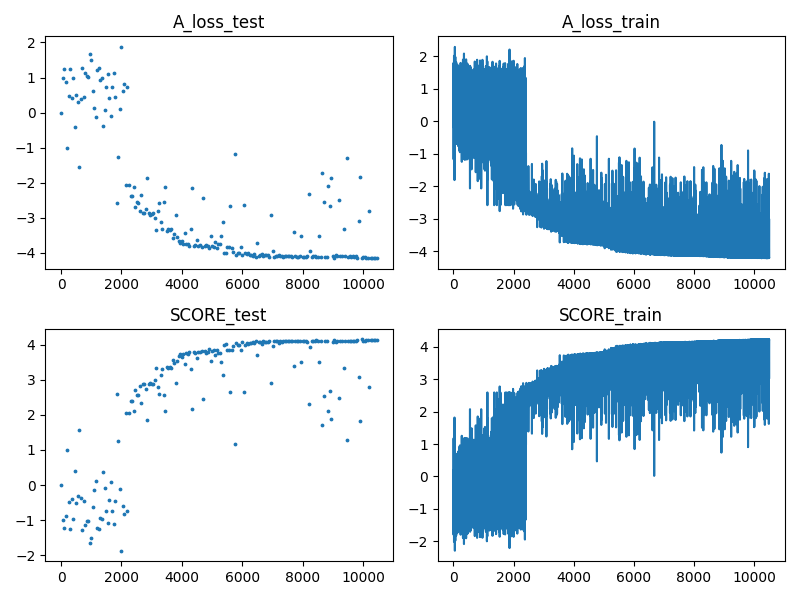
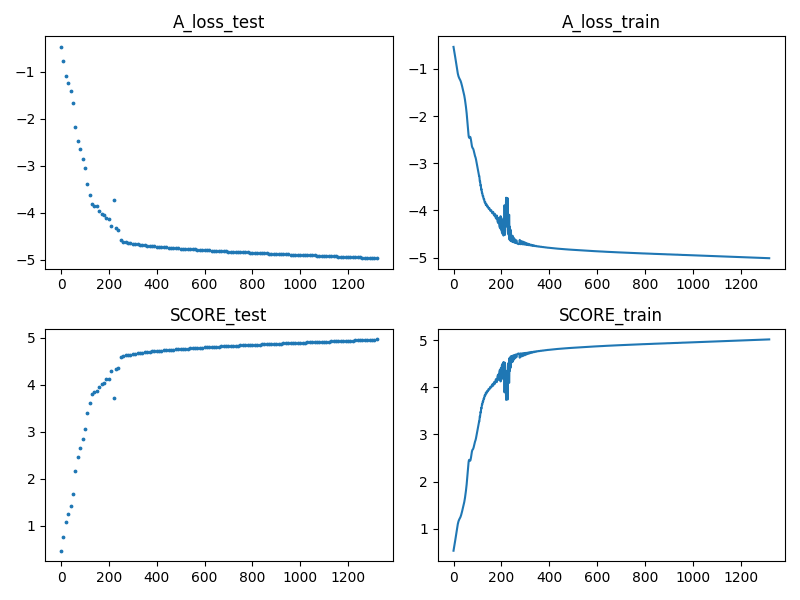
- AdamW (for comparison):
pip install grad-free-optimimport torch as tc
from pymoo.algorithms.soo.nonconvex.ga import GA as Algo
from trading_models.simple_models import MLP
from trading_models.utils import mod_keys, train_model
from grad_free_optim.pymoo import GradFreeOptim
def make_data():
x = tc.rand((100, 1))
yt = x**2
return dict(x=x, yt=yt)
def loss_fn(data, mode):
x, yt = data["x"], data["yt"]
y = net(x)
loss = tc.log10(((y - yt) ** 2).mean())
info = {"SCORE": -loss}
plots = {}
return loss, mod_keys(info, mode), mod_keys(plots, mode)
tc.manual_seed(0)
net = MLP([1, 32, 32, 1])
train_data, test_data = make_data(), make_data()
if 1:
bound = [-1.0, 1.0]
opt = GradFreeOptim(bound, net, train_data, test_data, loss_fn)
opt.run(Algo())
else: # AdamW
train_model(net, train_data, test_data, loss_fn)