![]()


A pilot ontology for the semantic exploitation of data assets in the Agri-food (EDAA) context, aligned with the IDSA Information Model and the BIGOWL ontology.
Note
Latest stable: see src/0.3.2/ (ontology, shapes, examples, vocabularies) and the rendered docs under GitHub Pages.
Check out the demo/ folder for a practical example of transforming a DCAT catalog to EDAAnOWL RDF.
The purpose of EDAAnOWL is to serve as an annotation ontology that enriches the description of Data Space assets. It allows for modeling the functional profile (inputs, outputs, parameters) of ids:DataApp and ids:DataResource, facilitating their semantic discovery, composition into complex services, and compatibility validation.
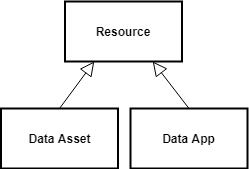
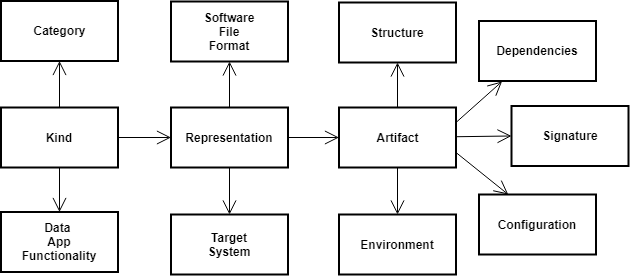
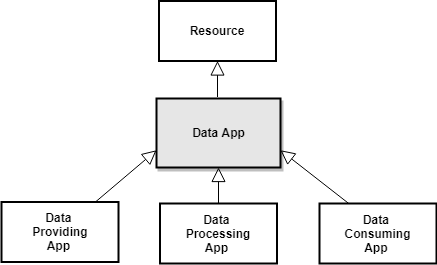
- What it is: The International Data Spaces Association (IDSA) Information Model defines a common vocabulary for resources (data and apps), their representations, endpoints, usage contracts, participants, connectors, and security profiles. It provides a canonical taxonomy for
ids:Resourceand content/context views to describe how resources are exposed and governed. - How it works: Key concepts include:
ids:Resource→ specialized intoids:DataResourceandids:DataApp/ids:SmartDataApp.ids:Representationcapturing format/media type/language, linked from resources byids:representationorids:defaultRepresentation.- Usage control with contracts and rules (ODRL-based), endpoints for access, and participant/connector/security profiles.
- Why we reuse it: We want assets and apps to be discoverable and governable across Data Spaces without reinventing core notions (resource taxonomy, representation, policies, endpoints). Aligning with IDSA ensures compatibility with IDS-based tooling and documentation.
- References:
- IDSA IM docs: https://international-data-spaces-association.github.io/InformationModel/docs/index.html#Resource
- Figures (examples):
{kind=link}
{kind=link}
{kind=link}
- What it is: A family of ontologies for analytical workflows, algorithms, problems, data, and components. It formalizes workflow elements (e.g.,
bigwf:Component), data types (bigdat:Data), and their relations. - How it works: Workflows are composed of components with well-defined inputs/outputs. These can be linked to algorithms/problems, enabling reproducible compositions and reasoning about compatibility.
- Why we reuse it: We need to express the computational side (pipelines, components, inputs/outputs) and connect IDSA “apps” to executable workflow elements. BIGOWL gives us a neutral, modular way to do so, avoiding bespoke, ad-hoc workflow modeling.
EDAanOWL provides the “connective tissue” between IDSA’s resource/contract governance and BIGOWL’s workflow semantics:
-
Classes (why we created/extended them)
:DataAsset ⊑ ids:DataResource: We specialize IDSA’s data resource to attach domain semantics (e.g., observable variables) needed for matchmaking and discovery.ids:SmartDataAppspecializations (:PredictionApp,:AnalyzerApp,:VisualizationApp): We align with IDSA’s app branch and provide a practical taxonomy reflecting functionality (prediction/analysis/visualization) inspired by IDSA’s Data App taxonomy.:DataProfile: Encapsulates structural/semantic “signatures” of data (class, CRS, resolutions, observed properties). This lives alongside IDSAids:Representation(format/media/language), not replacing it—complementary roles.:ObservableProperty ⊑ sosa:ObservableProperty: We reuse SOSA/SSN for domain variables (e.g., NDVI, temperature), enabling semantic I/O specifications for apps and semantic descriptions for assets.
-
Object properties (motivations)
:conformsToProfile (ids:Resource → :DataProfile): A resource states it conforms to a profile (structural/semantic signature). Motivates profile-based compatibility checks.:requiresProfile/:producesProfile (ids:DataApp ↔ :DataProfile): Apps specify expected/produced data signatures to enable structural compatibility.:requiresObservableProperty/:producesObservableProperty (ids:SmartDataApp ↔ :ObservableProperty): Apps declare semantic I/O needs—enables simple, meaningful matchmaking (semantic compatibility).:servesObservableProperty (:DataAsset ↔ :ObservableProperty): Assets declare the variables they provide—completing the matchmaking triangle.:implementsComponent (ids:DataApp ↔ bigwf:Component): Bridges IDSA apps to BIGOWL components, grounding apps in executable workflow units.:realizesWorkflow (ids:DataApp ↔ opmw:WorkflowTemplate): Links apps to abstract workflows (OPMW) for documentation and reasoning.:hasDomainSector (⊑ dcat:theme): DCAT-aligned domain tagging using SKOS schemes, ensuring interoperable cataloguing and filtering across domains.:hasCRS: Links to a formal Coordinate Reference System (e.g., EPSG URI).:supportContact: Standard contact point for support, using vCard (fn, email, telephone, URL).:legalContact: A specific contact point for legal inquiries about the resource.
-
Data properties (motivations)
dcat:spatialResolutionInMeters,dcat:temporalResolution,dcat:spatialResolutionInDegrees: Adopted from DCAT 3 to capture EO and time-series constraints for practical matchmaking.- Metrics (
:Metricand subtypes with:metricName/:metricValue/:metricUnit/:computedAt): Allows publishing quality/performance indicators relevant to governance and selection. :metricType: Links a metric to a standardized:MetricTypefrom the controlled vocabulary (metric-types.ttl), enabling interoperable metric names across data spaces.:accessType: Indicates the primary access mode for the resource (e.g., download, compute, ...).:alternativeName: Alternative title or name for a resource.:auditLogAvailable: Indicates if audit logs for the resource usage are available.:isAlive: Indicates if the dataset is actively maintained and expects future updates.:knownLimitations: Human-readable description of any known limitations, biases, or quality issues of the resource.:paymentModelDescription: A human-readable description of the pricing or payment model (e.g., 'Monthly Subscription', 'Pay-per-use').:qualityReportURI: Link to full quality report.:qualityScore: A quantitative quality score (e.g., 0-100) assigned by the external quality report.:recommendedUse: Human-readable description of the intended or recommended use cases for the resource.:refundPolicy: A text description of the refund policy applicable to the resource.schema:thumbnailUrl: A URL pointing to a thumbnail image for the resource.
-
Why both Profile-based and Direct Semantic models?
- Real-world data/app compatibility has two complementary facets:
- Structural: “Does my dataset’s structure/CRS/resolution match the app’s expectations?” →
:DataProfile. - Semantic: “Do I have NDVI/temperature that this app needs?” →
:ObservableProperty.
- Structural: “Does my dataset’s structure/CRS/resolution match the app’s expectations?” →
- Keeping both enables robust, explainable matchmaking and aligns with IDSA’s content view (representations) without conflating structure with format/serialization.
- Real-world data/app compatibility has two complementary facets:
-
Why align with IDSA Representation instead of embedding formats in profiles?
- IDSA prescribes
ids:Representationfor format/media/language; we follow that and keep:DataProfilefor data semantics/shape. This mirrors IDSA’s own separation of “content” vs. “context” and avoids duplication.
- IDSA prescribes
-
Why SKOS/DCAT/ODRL/PROV/LOCN/GeoSPARQL?
- We adopt standards recommended by IDSA and the Linked Data community. This maximizes interoperability and reduces custom modeling.
- IDSA-IM (v4): Core model for resources, apps, and governance.
- DCAT (v3): For cataloguing assets.
- ODRL (v2.2): For usage control policies.
- SOSA/SSN: For observable properties, sensors, and observations.
- GeoSPARQL (v1.1): For geospatial coverage.
- OPMW/BIGOWL: For workflow and component modeling.
- PROV-O: For provenance and lineage tracking (
prov:wasGeneratedBy,prov:wasDerivedFrom). - SKOS: For the modular vocabularies.
- Main Ontology: A semantic "bridge" linking
ids:DataApptobigwf:Component(from BIGOWL). - Profile Model: A
:DataProfileclass to describe the data "signatures" (inputs/outputs) of assets. - Data Lineage & Provenance: Support for tracking dataset generation (
prov:wasGeneratedBy) and derivation chains (prov:wasDerivedFrom) using PROV-O properties. - Modular Vocabularies: Separate, resolvable SKOS vocabularies for domains, observed properties, etc., versioned alongside the main ontology.
- Persistent Identifiers: All ontology and vocabulary modules are resolvable via https://w3id.org/EDAAnOWL/ for robust content negotiation.
- Automated Documentation & CI/CD: A GitHub Actions workflow (
release.yml) that, upon creating a new release:- Builds comprehensive HTML documentation with Widoco.
- Post-processes the HTML (
sed) to ensure all vocabulary links are correctly versioned. - Publishes all artifacts (docs, vocabs, RDF serializations) to the
gh-pagesbranch.
- Versioning: Supports a
latestdevelopment version and immutable, versioned snapshots (e.g.,/0.0.1/). - Practical Examples: See USE_CASES.md for real-world examples of semantic matchmaking and provenance tracking.

EDAAnOWL bridges three key layers:
- Data Space Layer: Real-world assets and applications
- Semantic Layer: IDSA model integration and semantic descriptions
- Workflow Layer: BIGOWL components and workflow definitions
📘 For detailed architecture documentation, see ARCHITECTURE.md
Use the “Cite this repository” button on the right (GitHub sidebar), which is generated from our CITATION.cff. It provides BibTeX, APA, and more.