Here are presented two algorithms that work in continuous enviroments:
*DDPG : https://spinningup.openai.com/en/latest/algorithms/ddpg.html
*TD3: https://spinningup.openai.com/en/latest/algorithms/td3.html
In 'main_function' we can change parameters to train some Agents with different configurations.
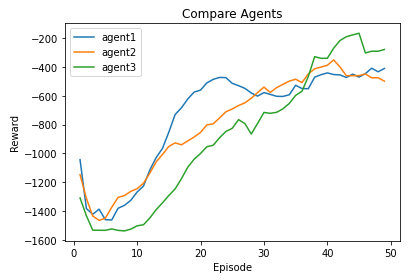
Here are some training results:
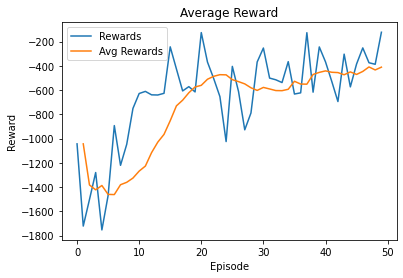
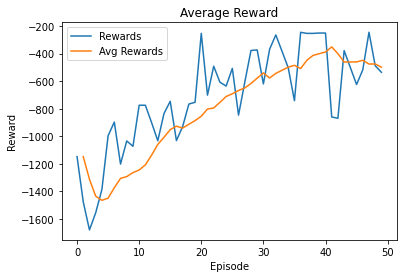
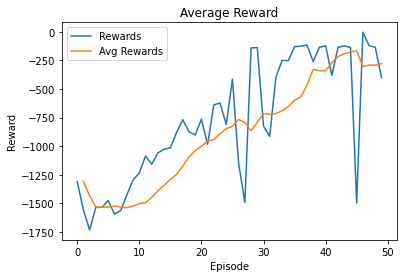
Configuration:
Agent1_DDPG (hidden_l1 =250, hidden_l1 =250, actor_lr =1e-4, critic_lr =1e-3, gamma =0.99, tau =1e-2, memory_size =50000, num_of_hd_layers =2)
Agent2_DDPG (hidden_l1 =350, hidden_l1 =350, actor_lr =1e-4, critic_lr =1e-3, gamma =0.99, tau =1e-2, memory_size =50000, num_of_hd_layers =2)
Agent3_TD3 (hidden_l1 =350, hidden_l1 =350, actor_lr =1e-4, critic_lr =1e-3, gamma =0.99, tau =1e-2, memory_size =50000, num_of_hd_layers =2, popicy_delay =2)
The 'train()' method can return the average rewards and we can store it in some variables. Thus we can train multiple Agents with different parameters and compare their evolutions.