int dir[8][2]={{-2,-1},{-1,2},{2,1},{-1,-2},{-2,1},{1,2},{2,-1},{1,-2}};//马走日 (马的方向)万能头文件
#include<bits/stdc++.h>
#include<iostream>
#include<cstdio>
#include<algorithm>
#include<cstring>
#include<string>
#include<utility>
#include<vector>
#include<set>
#include<stack>
#include<queue>
#define repr(i,n) for(int i=1;i<=n;i++)
#define rep(i,n) for(int i=0;i<n;i++)
#define pi pair<int>
#define ll long long
using namespace std;
int dir[8][2]={{-2,-1},{-1,2},{2,1},{-1,-2},{-2,1},{1,2},{2,-1},{1,-2}};//马走日 (马的方向)
const int N=1e5+5;
int main()
{
return 0;
} //模板
#include<iostream>
#include<string>
#include<queue>
#include<cstring>
#include<algorithm>
#define ll long long
using namespace std;
const int N=1e3+5;
string e[N];
int n,m,ex,ey,vis[N][N],dir[4][2]={0,1,1,0,0,-1,-1,0},res;
struct node{
int x,y,step;
node(int x,int y,int step):x(x),y(y),step(step){}
};
void bfs()
{
queue<node>q;
while(!q.empty())q.pop();
q.push(node{0,0,0});
vis[0][0]=1;
while(!q.empty())
{
node h=q.front();
if(h.x==ex&&h.y==ey)
{
res=h.step;
return ;
}
q.pop();
for(int i=0;i<4;i++)
{
int x=h.x+dir[i][0];
int y=h.y+dir[i][1];
if(x>=0&&x<n&&y>=0&&y<m&&e[x][y]!='*'&&!vis[x][y])
{
vis[x][y]=1;
q.push(node{x,y,h.step+1});
}
}
}
}
int main()
{
int t;
cin>>t;
while(t--)
{
cin>>n>>m>>ex>>ey;//n行m列终点坐标
ex-=1,ey-=1;
for(int i=0;i<n;i++)
cin>>e[i];
bfs();
cout<<res<<endl;
}
return 0;
}int BF(char s[],char t[],int pos)
{
int i=0,j=0;
int lens=strlen(s),lent=strlen(t);
while(i<lens&&j<lent)
{
if(s[i]==t[j])//匹配成功
{
++i;++j;
}
else//匹配不成功
{
i=i-j+1;//i重新匹配
j=0;
}
}
if(j==lent)return i-j;//返回匹配成功时第一个字符的下标
else return -1;//没有与s串匹配成功
}int BF(char s[],char t[],int pos)
{
int i=0,j=0,res=0,lens=strlen(s),lent=strlen(t);
while(i<lens)
{
while(i<strlen(s)&&t<strlen(t))
{
if(s[i]==t[j])
{
++i;++j;
}
else
{
i=i-j+1;
j=0;
}
}
if(j==lent)res++;//求能够匹配多少个子串
if(i==lens)return res;
else
{
i=i+j-1;
j=0;
}
}
}**思路:**都从下标0开始匹配,当出现匹配不成功时,t串从0开始,s串从i-j+1开始继续。
先解释字符串的前后缀
给定串:ABCABA
前缀:A,AB,ABC,ABCA,ABCAB,ABCABA 真前缀:A,AB,ABC,ABCA,ABCAB
后缀:A,BA,ABA,CABA,BCABA,ABCABA 真后缀:A,BA,ABA,CABA,BCABA
#include<iostream>
#include<cstring>
using namespace std;
const int maxn=1e6+5;
char s[maxn],t[maxn];
int nextp[maxn],lens,lent;
void get_next()//获取next数组
{
int i=0,j=-1;
nextp[0]=-1;
while(i<lent)
{
if(j==-1||t[i]==t[j])
nextp[++i]=++j;
else
j=nextp[j];//失配
}
}
void KMP()
{
int i=0,j=0,res;//从0位开始匹配res(子串在主串中有多少个可匹配的子串)
while(i<lens)
{
if(j==-1||s[i]==t[j])
{
++i;++j;
}
else
j=nextp[j];
if(j==lent)//匹配成功
{
res++;
j=nextp[j];
}
}
return res;
}
int main()
{
cin>>s>>t;
lens=strlen(s);
lent=strlen(t);
get_next();
cout<<KMP()<<endl;
return 0;
} next[i]=k表示从0~i-1位置子串的前缀和后缀相同的最大长度为k,并且k代表着与当前,后缀最大匹配的前缀位置。
| 下标 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 字符串 | a | a | b | a | a | b | a | a | b | a | a | b | |
| next[] | -1 | 0 | 1 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
next[12]=9,9所在的下标前缀= aabaabaab 与后缀aabaabaab是最大匹配
即next[i]=k,表示前i个的的最大公共前后缀匹配长度为k
#include<iostream>
#include<cstring>
#include<string>
using namespace std;
string str;
int nextp[100005];
void get_next()//获取next数组
{
int i=0,j=-1;
nextp[0]=-1;
while(i<str.size())
{
if(j==-1||str[i]==str[j])
nextp[++i]=++j;
else
j=nextp[j];//失配
}
}
int main()
{
cin>>str;
get_next();
for(int i=0;i<=str.size();i++)
cout<<nextp[i]<<" ";
return 0;
} 理解前缀和后缀的概念,"前缀"指除了最后一个字符以外,一个字符串的全部头部组合;"后缀"指除了第一个字符以外,一个字符串的全部尾部组合
/*
求a,b的公共字符串后缀=str,然后再求str和c的公共字符串,以此类推
其实就是模拟题
*/
#include<iostream>
#include<string>
#include<algorithm>
using namespace std;
const int N=2e2+5;
string f(string a,string b)//求a,b字符串的公共字符串后缀
{
string ans="";
for(int i=a.length()-1,j=b.length()-1;i>=0&&j>=0;i--,j--)
{
if(a[i]==b[j])
ans+=a[i];
}
return ans;
}
int main()
{
int n;
string a,b,s[N],str;
while(cin>>n&&n)
{
for(int i=0;i<n;i++)
cin>>s[i];
str=f(s[0],s[1]);
reverse(str.begin(),str.end());//求的str是后缀的公共字符串如果继续,需要反转以下才能继续
for(int i=2;i<n;i++)
{
str=f(str,s[i]);
reverse(str.begin(),str.end());//记得反转,在algorithm下
}
cout<<str<<endl;
}
return 0;
}
//[传送门](https://www.acwing.com/problem/content/781/)字符串最大跨距
题意:给定S和S1,S2,其中S1在S的左边并且是他的子串,S2在S右边是他的子串,且S1右边界小于S2的右边界,求他们之间的最大距离,其中会有重复的子串
#include<iostream>
#include<string>
using namespace std;
int main()
{
string str,S1,S2;
char c;
int i=0;
while(cin>>c)//输入格式
{
if(c!=',')
{
if(i==0)str+=c;
else if(i==1)S1+=c;
else if(i==2)S2+=c;
}else i++;
}
int s1,s2;
s1=str.find(S1);
s2=str.rfind(S2);
if(s1!=-1&&s2!=-1&&s1+S1.size()-1<s2)
cout<<s2-s1-S1.size();
else cout<<"-1";
cout<<endl;
//cout<<s1<<" "<<s2<<endl;
return 0;
}
//[传送门](https://www.acwing.com/problem/content/780/)
//回车 加ctrl+z查看结果子串必须是连续的,而子序列可以是不连续的
构造题:https://ac.nowcoder.com/acm/contest/6037/C//埃氏筛(求n以内的素数)
#include<iostream>
#include<cstdio>
#include<cmath>
using namespace std;
int vis[N];
void prime(int n)
{
vis[1]=1;//1肯定不是素数
for(int i=2;i<=cnt;i++)//从2开始到cnt枚举
{
if(!vis[i])
{
for(int j=i<<1;j<=cnt;j+=i)
vis[j]=1;//素数的倍数一定是素数
}
}
}
int main()
{
int n;
scanf("%d",&n);
prime();
return 0;
}//给定一个数判断他是不是素数,并且给出他的素因子
//https://ac.nowcoder.com/acm/problem/14399
/*
由于数据范围很大(n<=1e9),采用试除法,我们只需要判断2~sqrt(n),即可判断一个数是不是素数,然后在判断的过程中统计素因子(也就是所有的因子中是素数的)当n能够被i整除,说明一定不是素数,这个时候统计他的素因子,记得把所有n/i除尽,while(n%i==0)n/=i,当n==1说明统计完毕
*/
#include<iostream>
#include<cmath>
#include<vector>
using namespace std;
int main()
{
int n,t;
cin>>t;
while(t--)
{
cin>>n;
vector<int>res;
int x=sqrt(n);
bool flag=false;
for(int i=2;i<=x;i++)
{
if(n%i==0)
{
flag=true;
res.push_back(i);
while(n%i==0)
n/=i;
}
if(n==1)break;//不必在取统计
}
if(!flag)
{
cout<<"isprime"<<"\n"<<n<<"\n";
}
else
{
cout<<"noprime"<<"\n";
for(int i=0;i<res.size()-1;i++)//输出因子
cout<<res[i]<<" ";
cout<<res.back();//避免最后末尾有空格
if(n!=1)cout<<" "<<n;//还有素因子没被统计(例如21 7不会被统计,必须特判)
cout<<"\n";
}
}
return 0;
} 一维前缀和,顾名思义,就是 sum[i]=sum[1]+sum[2]+……sum[i]
适用于在O(n)的预处理后,可以在O(1)查询sum[l,r]=sum[r]-sum[l-1]
和暴力求区间和比起来,暴力的时间复杂度在n很大的时候就不行了
问题:询问区间和(a[i]~a[j])
for(int i=1;i<=n;i++)cin>>a[i];
for(int i=1;i<=n;i++)sum[i]=sum[i-1]+a[i];然后就可以在O(n)的时间循环
求a[i]~a[j]
sum[j]-sum[i-1]友好搭档:给定一个主串H和一个模式串S,求在主串H中有多少个子串和模式串S等价---地址(传送门)
等价的定义:两个字符串按照字典排序后相同,则认为等价字符串
解析:前缀和的思想,开两个int a[26],先统计模式串中各个字符的次数,然后枚举主串,以模式串长度为一个区间进行比较,两者的字符串中各个字符出现的次数相等,则等价,!注意每次枚举一个区间后要把前边的区间给删掉
具体做法:
int cnt_t[26],cnt_s[26];
for(int i=0;i<t.size();i++)//枚举主串
{
cnt_t[t[i]-'a']++;
if(i>=s.size())//从第一个区间结束后就要把前边的区间给删掉
cnt_t[t[i-s.size()]-'a']--;
if(judge())//直接写个判断两个子串是否相等的函数即可
ans++;
}
//也可以用vector来写,更加方便,不用自己再写判断函数,具体做法如下:
vector<int>cnt_t(26),cnt_s(26);
for(int i=0;i<t.size();i++)
{
cnt_t[t[i]-'a']++;
if(i>=s.size())
cnt_t[t[i-s.size()]-'a']--;
if(cnt_t==cnt_s)ans++;//两个vector相等即容量相等,所处位置的元素相等
}
//完整ac算法
#include<iostream>
#include<vector>
#include<string>
using namespace std;
string s,h;
int ans;
vector<int>cnts(26),cntt(26);
int main()
{
cin>>s>>h;
for(int i=0;i<s.size();i++)//统计子串中每个字符的个数
cnts[s[i]-'a']++;
for(int i=0;i<h.size();i++)
{
cntt[h[i]-'a']++;
if(i>=s.size())
cntt[h[i-s.size()]-'a']--;//只统计长度为lens区间的字符串个数
if(cnts==cntt)//相等说明2个vector具有相同的容量。所有位置的元素相等
ans++;
}
cout<<ans<<endl;
return 0;
} 在一维的基础上,画图更容易理解,dp[i] [j]代表从dp[1] [1]到dp[i] [j]所围成的矩阵之和,那么我们第一步就是先构造前缀和,dp[i] [j]=dp[i-1] [j]+dp[i] [j-1]-dp[i-1] [j-1] (通过第一张图很直观的能够看出来)
接下来就是对于询问,求dp[x1] [y1]和dp[x2] [y2]之间的区域求和,dp[x2] [y2]-dp[x1-1] [y2]-dp[x2] [y1-1]+dp[x1-1] [y1-1]

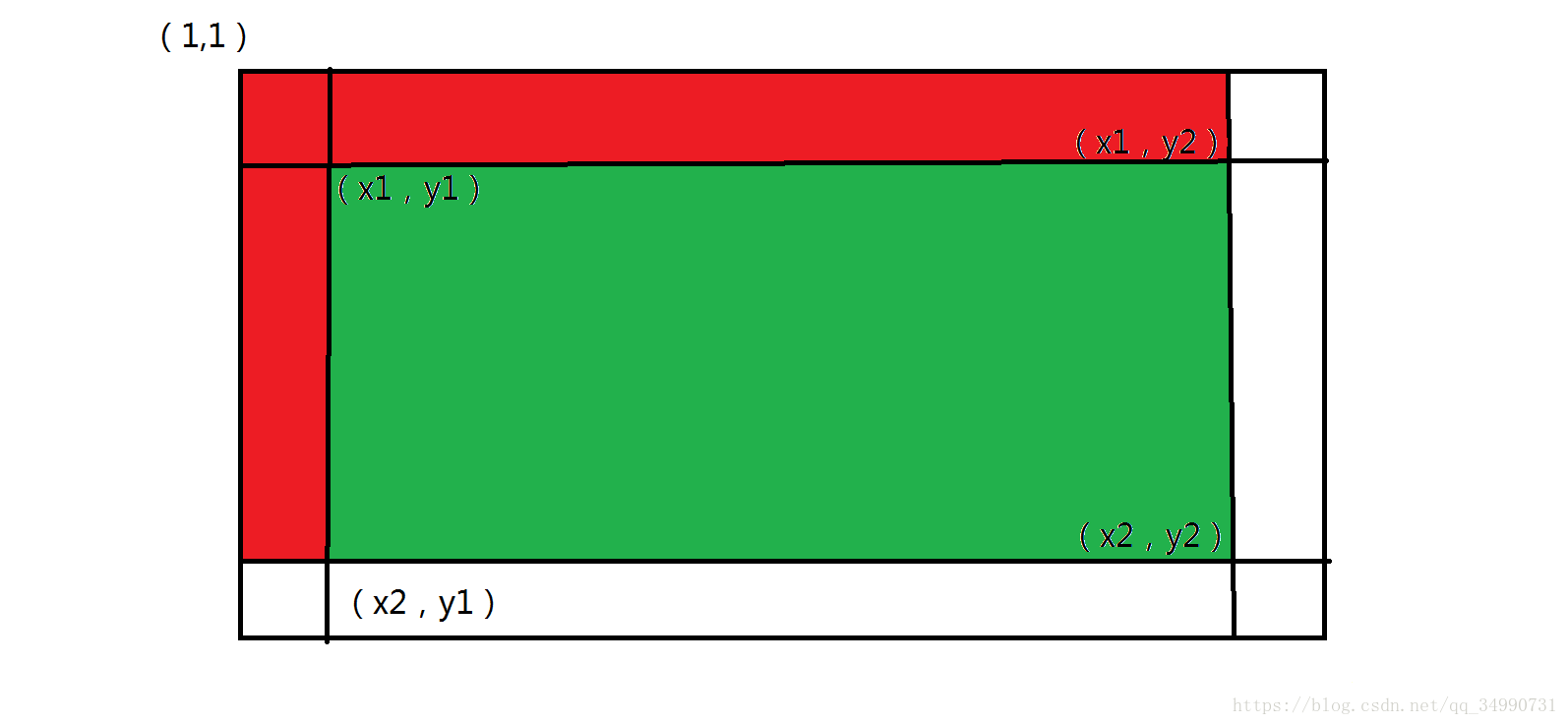
#include<iostream>
#include<cstdio>
using namespace std;
const int maxn=1e3+5;
int e[maxn][maxn];
long long dp[maxn][maxn];
int main()
{
int n,m,q;
cin>>n>>m>>q;
for(int i=1;i<=n;i++)//二维数组
for(int j=1;j<=m;j++)
scanf("%d",&e[i][j]);
for(int i=1;i<=n;i++)//预处理
{
for(int j=1;j<=m;j++)
dp[i][j]=dp[i-1][j]+dp[i][j-1]-dp[i-1][j-1]+e[i][j];
}
int x2,y2,x1,y1;
while(q--)//进行q次询问,询问两个点之间矩阵和
{
scanf("%d%d%d%d",&x1,&y1,&x2,&y2);
printf("%lld\n",dp[x2][y2]-dp[x1-1][y2]-dp[x2][y1-1]+dp[x1-1][y1-1]);
}
return 0;
} 完美子串 来源:竟码蓝桥杯模拟赛 传送门
思路:

思路1,2(1,2的实现难度逐渐递增,后边给出1,2实现过程),很简单实现,重要的是思路3。对于完美子串,可以推出对于任意区间[i,j]都满足L大+R大=L小+R小,则推出R大-R小=L小-L大,所以我们从右端预处理以下,minx[i]代表从i到x的位置有多少个比x小的,maxx[i]代表从i到x有多少个比x大的,那么我们求出R大-R小 =j有多少个,然后在左端枚举L小-L大有多少个j即可
//思路3:
#include<iostream>
#include<map>
using namespace std;
const int N=1e5+5;
int a[N],ans,minx[N],maxx[N];
map<int,int>m;
int main()
{
int n,x,t;
scanf("%d%d",&n,&x);
for(int i=1;i<=n;i++)
{
scanf("%d",&a[i]);
if(a[i]==x)t=i;//找到这个位置
}
for(int i=t;i<=n;i++)//右端点前缀和处理
{
if(a[i]<a[t])minx[i]++;
else if(a[i]>a[t])maxx[i]++;
minx[i]+=minx[i-1];
maxx[i]+=maxx[i-1];
m[maxx[i]-minx[i]]++;//这里就是我们要找的R大-R小得个数key(maxx[i]-minx[i])代表上述思路的j
}
ans=m[0];//一开始在右端点就已经有满足的了,因为j=0,就代表大于和小于的个数相等
for(int i=t-1;i>=1;i--)//枚举左端点,这里一定是从左端点末尾开始,因为要用前缀和处理,从小到大开始处理不了i到x的大于和小于个数
{
if(a[i]<a[t])minx[i]++;
else if(a[i]>a[t])maxx[i]++;
minx[i]+=minx[i+1];
maxx[i]+=maxx[i+1];
ans+=m[minx[i]-maxx[i]];//这里就是我们要找的L小-L大=j看有多少个和R大-R小=j相等而通过key就直接能找到相等的个数
}
printf("%d\n",ans);
return 0;
}
/*思路1:暴力出奇迹,O(n^3)跑出30%数据
*/
#include<iostream>
using namespace std;
const int N=1e5+5;
int a[N],ans;
bool judge(int i,int j,int t)
{
int minx=0,max=0;
for(int k=i;k<=j;k++)
{
if(a[k]>a[t])
max++;
else if(a[k]<a[t])
minx++;
}
return minx==max;
}
int main()
{
int n,x,t;
scanf("%d%d",&n,&x);
for(int i=0;i<n;i++)
{
scanf("%d",&a[i]);
if(a[i]==x)t=i;
}
for(int i=0;i<n;i++)
{
for(int j=0;j<n;j++)
if(i<=t&&t<=j&&judge(i,j,t))
ans++;
}
printf("%d\n",ans);
return 0;
}
/*思路2:优美暴力,使用了前缀和思想,(提前预处理一下,处理过程如下)
minx[i]表示前1~i位置有多少个比x小的
maxx[i]表示1~i位置有多少个比x大的
然后我们枚举子串左右端点,枚举的过程中,判断该子串是否包含x并且他们的区间是否>x和<x的一样多,而判断某区间>x和<x是否一样多之间用
minx[j]-minx[i-1]==maxx[j]-maxx[i-1]即可
这个思路其实已经能干掉70%数据了,我在测试时只有最后两组数据没干掉,相对于蓝桥杯,能想到这个思路,估计已经能干掉大部分人了(QAQ),其实重点就是前缀和的处理(很巧妙,少了一层循环)
*/
#include<iostream>
using namespace std;
const int N=1e5+5;
int a[N],ans,minx[N],maxx[N];
int main()
{
int n,x,t;
scanf("%d%d",&n,&x);
for(int i=1;i<=n;i++)
{
scanf("%d",&a[i]);
if(a[i]==x)t=i;
}
for(int i=1;i<=n;i++)//预处理过程基本上就是核心了
{
if(a[i]<a[t])minx[i]++;
else if(a[i]>a[t])maxx[i]++;
minx[i]+=minx[i-1];
maxx[i]+=maxx[i-1];
}
for(int i=1;i<=n;i++)
{
for(int j=i;j<=n;j++)
if(i<=t&&j>=t&&(minx[j]-minx[i-1])==(maxx[j]-maxx[i-1]))
{
ans++;
//printf("%d %d\n",i,j);
}
}
// for(int i=1;i<=n;i++)
// printf("%d %d\n",minx[i],maxx[i]);
printf("%d\n",ans);
return 0;
}蓝桥杯省赛 K倍区间传送门
思路:同样也是前缀和思路预处理,找出关系即可
[[CQOI2009]中位数图]https://ac.nowcoder.com/acm/problem/19913
这道题跟完美子串是一模一样的问题,只不过换了一种说法。
思路:可以拿上述完美子串的思路3可以直接ac本题,接下来我们对上述思路3进行优化
/*
1:对于中位数,我们肯定知道对于一个序列(排好序后),以中位数x为分界线,左边比x小的数和右边比x大的数个数相同,直接的想法就是暴力枚举每一种可能的区间,判断b是否在区间以及是否满足排好序后(暴力的话大可不必排序这个区间,只需枚举区间中比b大的个数和比b小的个数即可)小的和大的一样多,这种方法时间复杂度O(n^3)
2:我们再此方法上对O(n^3)进行优化,我们是不是可以对这个排列预处理,也就是求前缀和,对于minx[i]表示前i个数中比b小的个数,maxx[i]表示前i个数中比b大的个数,那么我们只用两层循环就可以了O(n^2)。
思路3:也就是最优解,对于某个区间{L,R}
中位数b:左边---L小:表示在b左边比b小的个数
--L大:表示在b左边比b大的个数
中文书b:右边---R小:表示在b右边比b小的个数
--R大:表示在b右边比b大的个数
上述条件满足:L小+R小=L大+R大,变换一下:L小-L大=R大-R小=j 只要存在L小-L大=R大-R小 就说明这段区间{L,R}满足条件,
接下来我们枚举从b开始到n的区间,求前缀和,maxx[i]和minx[i],并且统计cnt[maxx[i]-minx[i]=j]++,也就是这个j的数量,这里用map统计即可(因为考虑到可能存在负值情况,或者在统计值j的时候+n防止越界),上述过程就是在从b右边开始统计j的数量,那么我们是不是再从b左边开始求minx[i]-maxx[i]=j的值(注意这里和变换那里条件要一样),统计这个j值的数量是不是就是对答案的贡献,当然在枚举做区间时,要记得res=cnt[0],这种情况要先被加进去(因为=0的情况已经符合条件了,不懂得模拟一下即可)。最后输出res即可
思路4:对思路3的优化,我们直接让这个区间中比b大的=1,比b小的=-1,那么直接用sum对右区间求前缀和,同时统计值的数量(这里看到其他的题解都是在统计的前把cnt[N]=1,然后又在统计过程中把cnt[0]贡献到答案中,而我是从b的位置开始统计相当于cnt[N]=1,然后统计完值,将res+=cnt[N]了,根据个人喜好把,理解即可),然后对左区间进行求后缀和,同时把贡献答案 */
//思路4的代码
#include<iostream>
using namespace std;
const int N=1e5+5;
int a[N],cnt[N>>1];//N>>1防止N过于大造成段错误(因为自己发生数组越界了QAQ)
int main()
{
int n,b,pos;
cin>>n>>b;
for(int i=1;i<=n;i++)
{
cin>>a[i];
if(a[i]>b)a[i]=1;
else if(a[i]<b)a[i]=-1;
else if(a[i]==b)a[i]=0,pos=i;
}
int sum=0,add=;
for(int i=pos;i<=n;i++)
{
sum+=a[i];
cnt[sum+n]++;
}
int res=0;
res=cnt[n],sum=0;
for(int i=pos-1;i>=1;i--)
{
sum+=a[i];
res+=cnt[n-sum];
}
cout<<res<<endl;
return 0;
}
差分可以在O(n)的时间内修改后进行O(1)查询
void insert(int l.int r,int x)
{
a[l]+=x;
a[r+1]-=x;
}
int main()
{
int l,r,x;
cin>>n>>q;
for(int i=1;i<=n;i++)//对这个数组中n个元素预处理
{
cin>>x;
insert(i,i,x);//修改区间的值,也就是对l-r这个区间增加x
//cin>>a[i];
}
while(q--)//进行q次询问
{
cin>>l>>r>>x;//每次修改区间值
insert(l,r,x);
}
for(int i=1;i<=n;i++)//最后求一下前缀和即是原数组在某区间修改q此后的值
a[i]=a[i]+a[i-1];
for(int i=1;i<=n;i++)//输出修改后的值
printf("%d ",a[i]);
return 0;
}[裸题](http://oj.hzjingma.com/p/40?view=classic)
[进阶问题5998 - 专用牛棚](http://oj.hzjingma.com/p/5998?view=classic)
//这个是差分应用多次修改,求修改后最大值
[7897愤怒的FlappyBird 20'](http://oj.hzjingma.com/p/7897?view=classic) //这道题相比上一道,感觉这道题更难,目的就是将问题转换成差分思想,单次更新+1,最后求单次更新最小值以及最小值出现的次数
//这两道进阶题更能体现差分的具体应用
[校门外的树](https://ac.nowcoder.com/acm/problem/16649)
//这道题,差分模板,但是当l数据范围在0~1e9时,我们就需要离散化了,可以试试离散化做做(虽然不用离散化,直接差分模板或者暴力都能AC,但还是要学下离散化做法,逃~)/*
5998 - 专用牛棚,这道题是差分的应用,不像裸的差分问题,直接一眼就能看出来是差分问题,这道题首先题意搞明白,有n头奶牛,产奶时间段在l到r,并且这个时间段奶牛不能被其他奶牛看见(言外之意就是给这个奶牛一个牛棚,而其他奶牛就不能进这个牛棚了),那么我们可以在每个奶牛他自己的时间段给他增加1个牛棚(也就是在区间l-r,进行+1操作,这里就是给他增加一个牛棚保证他在这个时间段可以产奶)最后我们通过差分操作在O(n)内就算出了区间操作,那么我们要的就是在某个时间点(注意这个是时间点)最大数(也就是进行区间修改后这个时间点的牛棚数最大,最大数满足我们在任意时间点都可以奶牛产奶而不被其他奶牛看见)
*/
#include<iostream>
#include<algorithm>
using namespace std;
const int N=1e6+5;
int a[N];
void insert(int l,int r)
{
a[l]+=1;
a[r+1]-=1;
}
int main()
{
int n,l,r;
cin>>n;
for(int i=1;i<=n;i++)
{
cin>>l>>r;//对区间+1
insert(l,r);
}
int res=0;
for(int i=1;i<=1e6;i++)//这个时间点最大在1e6
{
a[i]+=a[i-1];
res=max(res,a[i]);
}
cout<<res<<endl;
return 0;
}
/*
7897愤怒的FlappyBird
第一种思路就是枚举每一种高度,找出该高度下撞坏柱子数,并且判断是否是最小柱子数,以及飞行高度的数量,时间复杂度O(n*h),只能通过30%数据
*/
#include<iostream>
#include<cstdio>
using namespace std;
const int N=1e6;
int a[N];
int main()
{
int n,h,mincnt,flycnt;
scanf("%d%d",&n,&h);
for(int i=1;i<=n;i++)
scanf("%d",&a[i]);
mincnt=n;
for(int i=1;i<=h;i++)//枚举每一种高度
{
int cnt=0;
for(int j=1;j<=n;j++)//统计每种高度撞坏柱子数
{
if(j%2==1)
{
if(a[j]>=i)cnt++;
}
else
{
if(h-a[j]+1<=i)cnt++;
}
}
if(cnt<mincnt)//是否是最小柱子数量
{
mincnt=cnt;
flycnt=0;
}
if(cnt==mincnt)flycnt++;
//printf("%d ",cnt);
}
printf("%d %d\n",mincnt,flycnt);
return 0;
}
/*
7897愤怒的FlappyBird
第二种思路就是枚举每个柱子的位置,奇数位置柱子在1~h'(h'为该柱子的高度)都会被撞坏,偶数位置柱子在区间(h-h'+1~h)都会被撞坏。所以每次让这个区间+1,最后统计在每个高度的最小值,也就是会撞坏的柱子数量,顺便在统计一下有多少个这样的高度即可
*/
#include<iostream>
#include<cstdio>
using namespace std;
const int N=1e6;
int f[N],sum[N];
int main()
{
int n,h,mincnt,flycnt,x;
scanf("%d%d",&n,&h);
for(int i=1;i<=n;i++)
{
cin>>x;
if(i&1)
{
f[1]+=1;
f[x+1]-=1;
}
else
{
f[h-x+1]+=1;
f[h+1]-=1;
}
}
for(int i=1;i<=h;i++)
sum[i]=sum[i-1]+f[i];
mincnt=n,flycnt=0;
for(int i=1;i<=h;i++)
{
if(sum[i]<mincnt)
{
mincnt=sum[i];
flycnt=0;
}
if(mincnt==sum[i])
flycnt++;
}
printf("%d %d\n",mincnt,flycnt);
return 0;
} 贪心是一种思想,每次都是在寻找最优解。经典例题:过桥问题
/*思路:
n=1:a[0]
n=2:a[1]
n=3:a[0]+a[1]+a[2]
n>3:两种策略
假设由AB...YZ(n个人)
策略一:AZ,A,AY,A(此时剩下AB和....n-4个人)a[n-1]+2*a[0]+a[n-2]
策略二:AB,A,YZ,B(此时剩下AB和....n-4个人)2*a[1]+a[0]+a[n-1]
解释:策略一是让最快的带着最慢的走,最快的回来再继续带着次慢的走
策略二是先让最快的前两个过去,再让最快的回来,最慢的两个过去,再让次慢的回来
注意:以上模拟的是在n个人中让最慢的两个过桥,你会发现模拟一遍最快的两个都回到了原地,这是因为他们最快的两个任务就是把后n-2个人都送到桥那边,直到剩下不超过4个人的时候他们的任务就完成了,3个人以下只有一种策略是最优解,而n>3时有两种策略,我们比较两种策略的最优解也就是用时最小的(你想在每次送走2个之后我们都选择用时最短的是不是整体用时最短?你品,你细品!!!)
核心代码:
*/
for(int i=0;i<n;i++)
cin>>a[i];
while(n>=4)
{
if(a[n-1]+2*a[0]+a[n-2]>=2*a[1]+a[0]+a[n-1])//选择最短时间的策略
ans+=2*a[1]+a[0]+a[n-1];
else
ans+=a[n-1]+2*a[0]+a[n-2];
n-=2;//循环把接下来最慢的两个送到桥那边
}
if(n==3)ans+=a[0]+a[1]+a[2];//三个人先让a[0]带着a[2]过去,a[0]回来,在带着a[1]过去
if(n==2)ans+=a[1];//两个人直接过去选择的是最慢的作为时间
if(n==1)ans+=a[0];//一个人直接过去
//over

for(int i=0;i<n;i++)
{
cin>>a[i];
dp[i]=1;//预处理每个数本身就是一个以1位数为序列的递增序列
}
for(int i=0;i<n;i++)
{
for(int j=0;j<i;j++)
if(a[i]>=a[j])
dp[i]=max(dp[i],dp[j]+1);
}
sort(dp,dp+n);
cout<<dp[n-1];题目:Is Bigger Smarter?
地址:传送门
中文翻译:
就是找一个序列,体重严格递增,iq严格递减。
思路:将体重递增排序,iq递减排序,那么问题就变成了求iq的递减序列
注意事项:判断方面需要
if(e[i].w>e[j].w&&e[i].iq<e[j].iq&&dp[j]+1>dp[i])
{
dp[i]=dp[j]+1;
path[i]=j;//标记序列
}-
体重是严格递增的,所以需特判下体重是否严格递增,后边的就是递减序列的条件了
-
路径同时需要保存下来,(递归输出)
-
当前i保存紧跟他后边的那个数j
统计答案:
if(ans<=dp[i])
{
pos=i;
ans=dp[i];
}- 等号不能省,原因:前边可能有等长的序列,我们要的序列n尽可能大
输出答案:
- 递归输出,因为我们最后标记的是序列最后一个数,递归反着输出
int gcd(int a,int b)
{
return b==0?a:gcd(b,a%b);
}总结:该算法是求最大公约数,当两个数的gcd=1,那么他们是互质的
相关例题:约分(一个分子分母都很大的数)
//[两数之和]https://leetcode-cn.com/problems/two-sum-ii-input-array-is-sorted/submissions/简单的来说就是,当数据范围太大,数组放不下(数组大概也就能放1e7)就需要用到离散化
[校门外的树](https://ac.nowcoder.com/acm/problem/16649)
//这道题,差分模板,但是当l数据范围在0~1e9时,我们就需要离散化了,可以试试离散化做做(虽然不用离散化,直接差分模板或者暴力都能AC,但还是要学下离散化做法,逃~)
/*
离散化处理:对于m次操作,我们定义最多N=2*m个长度(可以类比成一个节点有两个子节点,左边2*i-1,右边2*i+1),结构体长度确定后,内部pos存储的是区间的位置,num存储区间端点的值,在处理输入时,就是总共m次操作,每次操作在2*i-1处保存左端点位置和他的值,右端点同样如此.然后在差分操作时,我们都是在左端点位置+1,右端点位置的下一位-1。这里需要排个序,按照位置的从小到大排序,枚举位置,当存在sum==1说明可能会是左端点(因为还有区间覆盖的情况)当sum==1&&a[i].num==1这个肯定是在左端点位置,我们只需统计答案即可,最后不要忘记最后一个位置与l之间还可能存在贡献答案的可能
*/
#include<iostream>
#include<algorithm>
using namespace std;
const int N=2e2+5;
struct node{
int pos,num;
bool operator < (const node&rhs)const{
return pos<rhs.pos;
}
}a[N];
int main()
{
int l,m;
cin>>l>>m;
for(int i=1;i<=m;i++)
{
int x,y;
cin>>x>>y;
a[2*i-1].pos=x;
a[2*i-1].num=1;
a[2*i].pos=y+1;
a[2*i].num=-1;
}
sort(a+1,a+2*m+1);
int sum=0,ans=0;
for(int i=1;i<=2*m;i++)
{
sum+=a[i].num;
if(sum==1&&a[i].num==1)//保证该位置在左端点
{
ans+=a[i].pos-a[i-1].pos;
}
}
ans+=l-a[2*m].pos+1;
cout<<ans<<endl;
return 0;
}
固定一个大小为k的窗口,每次滑动后求出窗口的最大值和最小值(单调队列)
#include<iostream>
#include<deque>
#include<cstdio>
using namespace std;
deque<int>q1,q2;
const int N=1e6+5;
int n,k,a[N];
void maxx()//窗口最大值同下
{
for(int i=0;i<n;i++)
{
while(!q1.empty()&&a[i]>a[q1.back()])
q1.pop_back();
if(!q1.empty()&&q1.front()<i-k+1)
q1.pop_front();
q1.push_back(i);
if(i>=k-1)cout<<a[q1.front()]<<" ";
}
cout<<endl;
}
void minx()
{
for(int i=0;i<n;i++)
{
while(!q2.empty()&&a[i]<a[q2.back()])//首先队列不空,其次当要插入元素小于窗口内元素,窗口内元素就要pop出去
q2.pop_back();
if(!q2.empty()&&q2.front()<i-k+1)//当最左端不在窗口内移除
q2.pop_front();
q2.push_back(i); //这里进入的是元素的下标
if(i>=k-1)cout<<a[q2.front()]<<" ";//当达到窗口开始出去元素
}
cout<<endl;
}
int main()
{
cin>>n>>k;
for(int i=0;i<n;i++)//n个数,窗口大小为k
scanf("%d",&a[i]);
minx();//窗口求最小值
maxx();//窗口最大值
return 0;
}
//时间复杂度O(n)
//模板题:http://oj.hzjingma.com/p/27?view=classic最大子序和问题:输入一个长度为n的整数序列,从中找出一段长度不超过M的连续子序列,使得整个序列的和最大。
问题分析:如果这个题目没有长度不超过m这个条件限制,就是一道动态规划入门题。(最大子段和)暴力枚举所有满足长度的子串,利用前缀和求其子串的和,时间复杂度O(nm)枚举两个端点会超时,那么我们就只枚举其右端点,快速的找左端点。枚举右端点j,在[j-m+1,j]中找一个左端点i,使得以j结尾的[i,j]区间连续子序和最大。
→[i,j]区间子序和为sum[j]-sum[i-1]
→sum[j]已经固定了,所以等价于找一个最小的sum[i-1].
这便是单调队列的经典应用了,题库P0027滑动窗口,
//这道题的细节很多,比如为什么要维护窗口m+1大小?为什么不需要if(i>=m)这个条件?其实就是从模板那里变形,掌握这道题更能能够理解单调队列的精髓吧
#include<iostream>
#include<deque>
#include<cstdio>
#include<algorithm>
using namespace std;
const int N=3e5+5;
int a[N],n,m,sum[N],res;
deque<int>q;
void maxx()
{
for(int i=1;i<=n;i++)
{
while(!q.empty()&&sum[i]<sum[q.back()])
q.pop_back();
if(!q.empty()&&q.front()<i-m)//这里应该维护的是m+1大小的窗口
q.pop_front();
q.push_back(i);
//if(i>=m)//其实这里不需要的因为我们求的是任意的sum[j]-sum[i-1]
//cout<<sum[i]-sum[]
res=max(res,sum[i]-sum[q.front()]);
}
}
int main()
{
cin>>n>>m;
for(int i=0;i<n;i++)
{
scanf("%d",&a[i]);
sum[i+1]=sum[i]+a[i];
}
res=a[0];//我们要找的是最大子序和,由于可能有负数最大和所以答案直接在元素内产生不会影响答案
maxx();
cout<<res<<endl;
return 0;
}
//if(i>=m)//其实这里不需要的因为我们求的是任意的sum[j]-sum[i-1]
//这个数据被卡,原因是:n=m=16222 我们直接求出来的是 sum[n]-min(sum[i),
//所以会错,因为我们的sum[j]任意 裸题:对于i这个位置求右边第一个比他大的数字的下标
#include<iostream>
#include<stack>
#include<cstdio>
using namespace std;
const int N=3e6+5;
int a[N],res[N];
stack<int>s;
void f(int n)
{
for(int i=1;i<=n;i++)
{
while(s.size()&&a[i]>a[s.top()])
{
res[s.top()]=i;
s.pop();
}
s.push(i);
}
}
int main()
{
int n;
scanf("%d",&n);
for(int i=1;i<=n;i++)
scanf("%d",&a[i]);
f(n);
for(int i=1;i<=n;i++)
printf("%d ",res[i]);
return 0;
}
//洛谷要开启O(2)才能ac,或者用数组模拟栈应该会过
//或者acwing600演示奶牛(裸题)RMQ(Range Minimum/Maximum Query)区间最值
#include<iostream>
#include<cstdio>
#include<algorithm>
#include<cstring>
#include<string>
#include<utility>
#include<vector>
#include<set>
#include<queue>
#include<stack>
#define repr(i,n) for(int i=1;i<=n;i++)
#define rep(i,n) for(int i=0;i<n;i++)
#define pi pair<int>
#define ll long long
using namespace std;
const int N=1e6+5;
ll a[N];
void build(int p,int l,int r)
{
if(l==r){tree[p]=a[l];return;}
int mid=l+r>>1;
build(p*2,l,mid);
build(p*2+1,mid+1,r);
tree[p]=tree[p*2]+tree[p*2+1];
}
void change(int p,int l,int r,int x,int num)//修改第x个数+num
{
if(l==r)
{
tree[p]+=num;return ;
}
int mid=l+r>>1;
if(x<=mid)change(p*2,l,mid,x,num);
else change(p*2+1,mid+1,r,x,num);
tree[p]=tree[p*2]+tree[p*2+1];
}
void find(int p,int l,int r,int x,int y)//查询 x到y的和
{
if(x<=l&&r<=y)return tree[p];
int mid=l+r>>1;
if(y<=mid)return find(p*2,l,mid,x,y);
if(x>mid)return find(p*2+1,mid+1,r,x,y);
return (find(p*2,l,mid,x,mid)+find(p*2+1,mid+1,r,mid+1,y));
}
void change()
int main()
{
int n;
for(int i=1;i<=n;i++)
cin>>a[i];
build(1,1,n);
return 0;
} #include<iostream>
#include<cstring>
#include<algorithm>
using namespace std;
struct BigNum{
int num[105],len;
}A,B,C;//利用结构体存储数字和长度
char str[105];
void add(BigNum &x,BigNum &y,BigNum &z)
{
int jw=0;//进位
z.len=max(x.len,y.len);
for(int i=0;i<=z.len;i++)//=z.len是因为最后有可能有进位的情况(把进位1也放进去)
{
z.num[i]+=x.num[i]+y.num[i]+jw;
jw=z.num[i]/10;
z.num[i]%=10;
}
//cout<<z.len<<endl;
if(z.num[z.len])
z.len++;
//cout<<z.len<<endl;
}
void print(BigNum &C){
for(int i=C.len-1;i>=0;i--)
cout<<C.num[i];
}
int main()
{
// 读取并倒序存储大整数A
cin>>str;
int len=strlen(str);
A.len=len;
for(int i=0;i<len;i++)//倒叙存储避免进位问题
A.num[len-i-1]=str[i]-'0';
// 读取并倒序存储大整数B
cin>>str;
B.len=len=strlen(str);
for(int i=0;i<len;i++)
B.num[len-i-1]=str[i]-'0';
add(A,B,C);//计算结果
print(C);//输出
return 0;
}对于add函数也可这样处理
void add(BigNum &x, BigNum &y, BigNum &z) {
z.len = max(x.len, y.len); // 结果最小长度为两者长度最大值
for(int i = 0; i < z.len; i++) z.num[i] = x.num[i] + y.num[i]; // 不进位加法得到初步结果
for(int i = 0; i < z.len; i++)
if(z.num[i] > 9) { // 进行逐位进位
z.num[i + 1] += 1;
z.num[i] -= 10;
}
if(z.num[z.len]) ++z.len; // 判断最高位是否有进位
}#include<iostream>
#include<vector>
#include<string>
#include<algorithm>//用高了reverse字符串反转
using namespace std;
string add(string &a,string &b)//&可以避免重复复制字符串
{
string c;//结果
int t=0;//每次按位计算,包括了进位
for(int i=a.size()-1,j=b.size()-1;i>=0||j>=0||t>0;i--,j--)//t>0是因为最后一次可能有进位出现而i,j已经<0
{
if(i>=0)t+=a[i]-'0';
if(j>=0)t+=b[j]-'0';
c+=t%10+'0';
t/=10;
}
reverse(c.begin(),c.end());
return c;
//cout<<c<<endl;
}
int main()
{
string a,b;
cin>>a>>b;
cout<<add(a,b)<<endl;
return 0;
}#include<iostream>
#include<vector>
#include<string>
#include<algorithm>
using namespace std;
vector<int> add(vector<int>&A,vector<int>&B)
{
if(A.size()<B.size())return add(B,A);
vector<int>C;
int t=0;
for(int i=0;i<A.size();i++)
{
if(i<B.size())t+=B[i];
t+=A[i];
C.push_back(t%10);
t/=10;
}
if(t)C.push_back(t);
return C;
}
int main()
{
string a,b;
vector<int>A,B,C;
cin>>a>>b;
for(int i=a.size()-1;i>=0;i--)A.push_back(a[i]-'0');
for(int i=b.size()-1;i>=0;i--)B.push_back(b[i]-'0');
C=add(A,B);
for(int i=C.size()-1;i>=0;i--)
cout<<C[i];
cout<<endl;
return 0;
}// C = A + B, A >= 0, B >= 0
vector<int> add(vector<int> &A, vector<int> &B)
{
if (A.size() < B.size()) return add(B, A);
vector<int> C;
int t = 0;
for (int i = 0; i < A.size(); i ++ )
{
t += A[i];
if (i < B.size()) t += B[i];
C.push_back(t % 10);
t /= 10;
}
if (t) C.push_back(t);
return C;
}
作者:yxc
链接:https://www.acwing.com/blog/content/277/
来源:AcWing
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。题目描述
楼梯有N阶,上楼可以一步上一阶,也可以一步上二阶。
编一个程序,计算共有多少种不同的走法。
N<=5000
输入格式
一个数字,楼梯数。
输出格式
走的方式几种。
输入样例
4
输出样例
5
**思路:**n的范围有点大,采用高精处理
#include<cstdio>
#include<algorithm>
#include<iostream>
#include<cstring>
using namespace std;
int n,len=1,f[5003][5003];//f[k][i]--第k阶台阶所对应的走法数
void hp(int k)//高精度加法,k来存阶数
{
int i;
for(i=1;i<=len;i++)
f[k][i]=f[k-1][i]+f[k-2][i];//套用公式
for(i=1;i<=len;i++) //进位
if(f[k][i]>=10)
{
f[k][i+1]+=f[k][i]/10;
f[k][i]=f[k][i]%10;
if(f[k][len+1])len++;
}
}
int main()
{
int i;
scanf("%d",&n);
f[1][1]=1; f[2][1]=2; //初始化
for(i=3;i<=n;i++) //从3开始避免越界
hp(i);
for(i=len;i>=1;i--) //逆序输出
printf("%d",f[n][i]);
return 0;
}通过字符串读取之后反向存入vector,判断A和B的关系A>B,计算sub(A,B)
否则计算sub(B,A)并且输出“-”。
#include<iostream>
#include<vector>
#include<string>
using namespace std;
bool cmp(vector<int> &A,vector<int> &B)
{
//判断A>B则ans>=0否则ans<0
if(A.size()!=B.size())return A.size()>B.size();//判断A是否大于B
for(int i=A.size()-1;i>=0;i--)//从高位开始判断
if(A[i]!=B[i])return A[i]>B[i];
return true;//说明ans=0
}
vector<int> sub(vector<int> &A,vector<int> &B)
{
vector<int>C;
for(int i=0,t=0;i<A.size();i++)
{
t+=A[i];
if(i<B.size())t-=B[i];
C.push_back((t+10)%10);
if(t<0)t=-1;
else t=0;
}
while(C.size()>1&&C.back()==0)C.pop_back();//消除高位的0,因为高位可能是两个相等的数相减所以会有0的情况
return C;
}
int main()
{
string a,b;
cin>>a>>b;
vector<int>A,B,C;
for(int i=a.size()-1;i>=0;i--)A.push_back(a[i]-'0');
for(int i=b.size()-1;i>=0;i--)B.push_back(b[i]-'0');
if(cmp(A,B))
{
C=sub(A,B);
for(int i=C.size()-1;i>=0;i--)
printf("%d",C[i]);
}else
{
printf("-");
C=sub(B,A);
for(int i=C.size()-1;i>=0;i--)
printf("%d",C[i]);
}
printf("\n");
return 0;
}1、模拟乘法规则,从A的个位到高位与B相乘,乘得的结果放入t中,则此位的数为t % 10.把t / 10剩余给下一个高位
2、若遍历完整个A,t > 0,则表示还有剩余的数,则需要将剩余的数继续补到下一个高位
//C = A * b, A >= 0, b >= 0
#include<iostream>
#include<vector>
#include<string>
#include<cstdio>
using namespace std;
vector<int> mul(vector<int> &A,int b)
{
vector<int>C;
for(int i=0,t=0;i<A.size()||t;i++)
{
if(i<A.size())t+=A[i]*b;
C.push_back(t%10);
t/=10;
}
while(C.size()>1&&C.back()==0)C.pop_back();//作用是消除大数*0的情况 例如123*0 ,如果不消除高位0,则会有3个0,但结果应该是有1个0
return C;
}
int main()
{
string a;
int b;
cin>>a>>b;
vector<int>A,C;
for(int i=a.size()-1;i>=0;i--)A.push_back(a[i]-'0');
C=mul(A,b);
for(int i=C.size()-1;i>=0;i--)
printf("%d",C[i]);
printf("\n");
return 0;
} 2 1 0 //在num[]中下标
---------
1 2 3 //a.num[]
* 3 2 //b.num[]
---------
2 4 6
+ 3 6 9
---------
3 9 3 6 //ans.num[]易发现:
- 乘法竖式中,
a.num[i]和b.num[j]相乘的结果,放在了ans.num[i+j]的位置。 a,b都为正整数时,长度为a.len和b.len的数字相乘得到ans,则a.len+b.len-1<=ans.len<=a.len+b.len
模拟上例竖式运算过程:
#include<iostream>
#include<vector>
#include<string>
using namespace std;
vector<int> mul(vector<int> &A,vector<int> &B)
{
vector<int>C(A.size()+B.size());// 最大长度
for(int i=0;i<A.size();i++)//模拟乘法竖式
{
for(int j=0;j<B.size();j++)
{
C[i+j]+=A[i]*B[j];
}
}
for(int i=0,t=0;i<C.size();i++)// 进位处理
{
t+=C[i];
if(i>=C.size())C.push_back(t%10);
else C[i]=t%10;
t/=10;
}
while(C.size()>1&&C.back()==0)C.pop_back();
return C;
}
int main()
{
string a,b;
cin>>a>>b;
vector<int>A,B,C;
for(int i=a.size()-1;i>=0;i--)A.push_back(a[i]-'0');
for(int i=b.size()-1;i>=0;i--)B.push_back(b[i]-'0');
C=mul(A,B);
for(int i=C.size()-1;i>=0;i--)
cout<<C[i];
cout<<endl;
return 0;
}
/*
进位处理也可以这样写
for(int i=0;i<C.size();i++)
{
C[i+1]+=C[i]/10;
C[i]%=10;
}
*/#include<iostream>
#include<vector>
#include<string>
#include<cstdio>
#include<algorithm>
using namespace std;
vector<int> div(vector<int> &A,int b,int &r)
{
vector<int>C;
r=0;
for(int i=A.size()-1;i>=0;i--)//从高位开始处理
{
r=r*10+A[i];
C.push_back(r/b);
r%=b;
}
reverse(C.begin(),C.end());
while(C.size()>1&&C.back()==0)C.pop_back();//除去0
return C;
}
int main()
{
string a;
int b,r;
cin>>a>>b;
vector<int>A,C;
for(int i=a.size()-1;i>=0;i--)A.push_back(a[i]-'0');
C=div(A,b,r);
for(int i=C.size()-1;i>=0;i--)
printf("%d",C[i]);
printf("\n");
printf("%d\n",r);
return 0;
}( a + b ) % c =(( a % c ) + ( b % c ))% c
a * b % c = (( a % c )*( b % c ))%c
思路:我们把 b 写成二进制,例如 b=110(2)
那 a^b = a^2 * a^4
我们可以从后往前遍历 b 的二进制的每一位,同时维护 a^2k, 假设 b 的该位二进制有 1, 就让答案乘上 a^2k
const int mod = 1e9 + 7;
int Pow(int a,int b) {
int res = 1;
for(;b;b>>=1,a=(long long)a*a%mod)
if(b & 1)
res = (long long)res * a % mod;
return res;
}
//另一种写法,p是取模
int qmi(int a,int b,int p)
{
int res=1%p,t=a;
while(b)
{
if(b&1)res=res*t%p;
t=t*t%p;
b=b>>1;
}
}
//例如 a^10=a^(1010)2=a^(1*2^3+0*2^2+1*2^1+0*2^0)=a^(1*2^3+1*2^1)
利用分治,我们可以把问题的规模不断的缩小,进而解决问题。
定义函数 Pow*(a,b) 为计算 a 的 b 次幂,按照 b的奇偶性进行分类讨论,如果 b是个偶数,那么答案应该等于 Pow(a,b/2)^2, 如果 b是个奇数,那么答案应该等于 Pow(a,b/2)^2* *a
考虑递归边界,当 b = 0的时候, x^0 = 1 ,所以直接返回 1 就可以了。
值得注意的是,取模的时候如果有 a和 b相乘,那么要记得看结果是否会超过 int ,判断的依据是模数的平方和 2*10^9
实现的时候记得储存算过的函数值,不要让他重复调用。
typedef long long ll;
const int mod=1e9+7;
ll Pow(ll a,ll b)
{
if(b==0)return 1;//递归边界
ll t=Pow(a,b>>1);// b >> 1 即是 b / 2
if(b&1) // b 是奇数 因为模数的平方大于 int 的最大值,所以记得强制转换为long long
retrun ((t*t)%mod*a)%mod;
else return (t*t)%mod;// b 是偶数
}快速幂与高精的结合:416.麦森数
一条路走到黑,走到头倒回去
暴力循环
//n的全排列需要n层循环
#include<iostream>
#include<cstdio>
using namespace std;
int main()
{
int n;
cin>>n;
for(int i=1;i<=n;i++)
{
for(int j=1;j<=n;j++)
{
if(j!=i)
for(int k=1;k<=n;k++)
{
if(k!=j&&k!=i)
printf("%d%d%d\n",i,j,k);
}
}
}
return 0;
} 搜索
# include<iostream>
# include<string.h>
using namespace std;
bool visit[100]={0};
int a[100];
void dfs(int cur,int n)
{
int i;
if(cur==n)
{
for(i=0;i<n;i++)
{
cout<<a[i];
}
cout<<endl;
}
else
{
for(i=1;i<=n;i++)
{
if(!visit[i])
{
a[cur]=i;
visit[i]=true;
dfs(cur+1,n);
visit[i]=false;
}
}
}
}
int main()
{
int n;
while(cin>>n&&n)
{
memset(a,0,sizeof(a));
dfs(0,n);
}
return 0;
}//紫书190
int a[35];//集合中的元素
void f(int n,int s)
{
for(int j=0;j<n;j++)
if(s&(1<<j))//s就是二进制的状态,而1<<j利用了非0即为真
printf("%d ",a[j]);
}
int main()
{
for(int i=0;i<1<<n;i++)//总共有2^n个子集
{
f(n,i);//将i变成二进制,而二进制的状态1就是选0就是不选
}
return 0;
}
/*
直接可以写成两个循环
*/
for(int i=0;i<1<<n;i++)
{
for(int j=0;j<n;j++)
if(i&(1<<j))
cout<<a[j]<<" ";//每个内层循环是为了输出每个子集
cout<<endl;
}
/*
1<<j解释:对于每个i都是一种子集(变成二进制),而我们在内层循环里要做的其实就是把这个二进制表示的01把其中的1所对应状态给选出来,而1<<j&i就是判断二进制下的i每一位其中有1的选出来。
其实这里也可以直接把i的二进制通过>>移位的操作选出1,具体操作如下
*/
for(int i=0;i<1<<n;i++)
{
int t=i;//因为t需要变化,所以用中间变量代替i
for(int j=0;j<n;j++)
{
if(t&1)
cout<<a[j]<<" ";//每个内层循环是为了输出每个子集
t>>1;//每次移位都要找出其中的1
}
cout<<endl;
}//其实就是用搜索的方法,选和不选的状态递归下去
#include<iostream>
using namespace std;
int a[3],b[3];
void dfs(int cur)
{
if(cur==3)
{
for(int i=0;i<3;i++)
if(b[i])cout<<a[i]<<" ";
cout<<"\n";
return ;
}
b[cur]=1;
dfs(cur+1);
b[cur]=0;
dfs(cur+1);
}
int main()
{
int n;
for(int i=0;i<3;i++)
cin>>a[i];
dfs(0);
return 0;
} /*
位向量法其实就是求子集生成,其实这是搜索的一种形式,通过选和不选两种状态我们可以解决很多其他问题,例如dp的背包问题
题意:有一个箱子容量V(0<=V<=20000),n个物品(0<n<=30),每个物品都有一个体积,求n个物品任取若干个装入箱内,使箱子的剩余空间最小。(也就是说把若干个物品放进箱子,尽量放满,不能溢出)--典型的背包问题
搜索思路:由于物品个数很小,考虑用搜索解决,因为是若干个物品,我们不知道物品个数,所以每个物品都有选和不选的状态。
链接:https://ac.nowcoder.com/acm/problem/16693
*/
#include<iostream>
#include<algorithm>
using namespace std;
int vis[35],res=0x3f3f3f3f,a[35];
void dfs(int cur,int v,int n,int sum)
{
if(sum>v)return ;
if(cur==n)
{
res=min(res,v-sum);
return ;
}
vis[cur]=1;
dfs(cur+1,v,n,sum+a[cur]);
vis[cur]=0;
dfs(cur+1,v,n,sum);
}
int main()
{
int v,n;
cin>>v>>n;
for(int i=0;i<n;i++)
cin>>a[i];
dfs(0,v,n,0);
cout<<res<<"\n";
return 0;
} 集合求和]:https://www.luogu.com.cn/problem/P2415
/*
#include<iostream>
#include<cstdio>
using namespace std;
const int N=35;
int main()
{
int n=0,a[N],sum=0,x;
while(scanf("%d",&x)!=EOF)
a[n++]=x;
for(int i=0;i<1<<n;i++)
{
int t=i;
for(int j=0;j<n;j++)
{
if(t&1)
sum+=a[j];
t>>1;
}
}
cout<<sum<<endl;
return 0;
}
//以上用二进制做的 60分,因为时间复杂度太大
*/
//其实这道题是结论题,对于求集合中所有子集之和,我们会发现集合中的每个元素在子集中出现的次数都是2^(n-1),所以res=sum*2^(n-1),sum是集合元素之和
#include<iostream>
#include<cstdio>
#include<cmath>
using namespace std;
typedef long long ll;
int main()
{
int n,x;
ll sum=0;
while(scanf("%d",&x)!=EOF)
sum+=x,n++;
cout<<ll(sum*pow(2,n-1))<<endl;
return 0;
} //以下是八皇后改(原题链接):https://www.dotcpp.com/oj/problem2087.html
#include<iostream>
#include<algorithm>
using namespace std;
int vis[3][20],res,e[8][8],c[8],n=8;
void dfs(int cur)
{
if(cur==n)
{
int sum=0;
for(int i=0;i<n;i++)
sum+=e[i][c[i]];
res=max(res,sum);
}
for(int i=0;i<n;i++)
{
if(!vis[0][i]&&!vis[1][cur+i]&&!vis[2][cur-i+n])
{
c[cur]=i;
vis[0][i]=vis[1][cur+i]=vis[2][cur-i+n]=1;
dfs(cur+1);
vis[0][i]=vis[1][cur+i]=vis[2][cur-i+n]=0;
}
}
}
int main()
{
for(int i=0;i<n;i++)
{
for(int j=0;j<n;j++)
cin>>e[i][j];
}
dfs(0);
cout<<res<<endl;
return 0;
}//原题链接:https://www.dotcpp.com/oj/problem1460.html
/*
蓝桥杯的真题:n*n棋盘放n个黑皇后和n个白皇后,要求同n皇后问题,并且地图上1能放0不能放皇后
思路:先放n个白皇后,并且给白皇后放过的地方做标记(防止后边放黑皇后放到白皇后的位置),然后放完,我们再放n个黑皇后,判断的时候记得白皇后放过的位置不能再放
问题:由于放n皇后是一行一列,所以我们就枚举每一行,也就不会出现同行放2个皇后,所以不需要判断同行的条件,然后就是cur表示当前行i表示当前列,所以[cur][i]就表示某行某列,还有就是vis的判断条件要分开写,不能用一个来判断黑白皇后的条件,这里利用二维数组做判断条件,比较方便
*/
#include<iostream>
#include<algorithm>
using namespace std;
int vis_white[3][20],res,e[8][8],n;
int white_e[8][8];
int vis_black[3][20];
void dfs_black(int cur)
{
if(cur==n)
{
res++;
return ;
}
for(int i=0;i<n;i++)
{
if(!vis_black[0][i]&&!vis_black[1][cur+i]&&!vis_black[2][cur-i+n]&&e[cur][i]==1&&!white_e[cur][i])
{
vis_black[0][i]=vis_black[1][cur+i]=vis_black[2][cur-i+n]=1;
dfs_black(cur+1);
vis_black[0][i]=vis_black[1][cur+i]=vis_black[2][cur-i+n]=0;
}
}
}
void dfs(int cur)
{
if(cur==n)
{
dfs_black(0);
}
for(int i=0;i<n;i++)
{
if(!vis_white[0][i]&&!vis_white[1][cur+i]&&!vis_white[2][cur-i+n]&&e[cur][i]==1)
{
//c[cur]=i;
white_e[cur][i]=1;
vis_white[0][i]=vis_white[1][cur+i]=vis_white[2][cur-i+n]=1;
dfs(cur+1);
//c[cur]=0;
white_e[cur][i]=0;
vis_white[0][i]=vis_white[1][cur+i]=vis_white[2][cur-i+n]=0;
}
}
}
int main()
{
cin>>n;
for(int i=0;i<n;i++)
{
for(int j=0;j<n;j++)
cin>>e[i][j];
}
dfs(0);
cout<<res<<endl;
return 0;
}//模板
#include<iostream>
#include<string>
#include<queue>
#include<cstring>
#include<algorithm>
using namespace std;
const int N=1e3+5;
string e[N];
int n,m,ex,ey,vis[N][N],dir[4][2]={0,1,1,0,0,-1,-1,0},res;
struct node{
int x,y,step;
node(int x,int y,int step):x(x),y(y),step(step){}
};
void bfs()
{
queue<node>q;
while(!q.empty())q.pop();
q.push(node{0,0,0});
vis[0][0]=1;
while(!q.empty())
{
node h=q.front();
if(h.x==ex&&h.y==ey)
{
res=h.step;
return ;
}
q.pop();
for(int i=0;i<4;i++)
{
int x=h.x+dir[i][0];
int y=h.y+dir[i][1];
if(x>=0&&x<n&&y>=0&&y<m&&e[x][y]!='*'&&!vis[x][y])
{
vis[x][y]=1;
q.push(node{x,y,h.step+1});
}
}
}
}
int main()
{
int t;
cin>>t;
while(t--)
{
cin>>n>>m>>ex>>ey;//n行m列终点坐标
ex-=1,ey-=1;
for(int i=0;i<n;i++)
cin>>e[i];
bfs();
cout<<res<<endl;
}
return 0;
}//裸题
P1443马的遍历:https://www.luogu.com.cn/problem/P1443
//进阶(after与迷宫)
https://ac.nowcoder.com/acm/problem/14608
//大致题意:从0,0,0开始走上下左右前后六个方向,走到n-1,n-1,n-1,其中.可以走,*不可以走,求最短距离
//原题:https://ac.nowcoder.com/acm/problem/201613
#include<iostream>
#include<queue>
using namespace std;
const int N=1e2+5;
int vis[N][N][N],n,res;
char e[N][N][N];
int dx[] = {0, 1, 0, -1 ,0 , 0}, dy[] = {1, 0, -1, 0, 0, 0}, dz[] = {0, 0, 0, 0, 1, -1};
struct node{
int x,y,z,step;
};
bool judge(int x,int y,int z)
{
if(x<0||x>=n||y<0||y>=n||z<0||z>=n)return false;
return true;
}
void bfs()
{
queue<node>q;
while(!q.empty())q.pop();
q.push(node{0,0,0});
vis[0][0][0]=1;
while(!q.empty())
{
node h=q.front();
if(h.x==n-1&&h.y==n-1&&h.z==n-1)
{
res=h.step;
return ;
}
q.pop();
for(int i=0;i<6;i++)
{
int x=h.x+dx[i];
int y=h.y+dy[i];
int z=h.z+dz[i];
if(judge(x,y,z)&&e[x][y][z]!='*'&&!vis[x][y][z])
{
vis[x][y][z]=1;
q.push(node{x,y,z,h.step+1});
}
}
}
}
int main()
{
cin>>n;
for(int i=0;i<n;i++)
for(int j=0;j<n;j++)
for(int k=0;k<n;k++)
cin>>e[i][j][k];
bfs();
if(res)
cout<<res+1;
else cout<<"-1";
cout<<"\n";
return 0;
} #include<iostream>
#include<string>
#include<vector>
#include<algorithm>
#include<cstring>
using namespace std;
const int N=1e2+5;
string e[4];
int vis[4][N],m,cnt;
void dfs(int x,int y)
{
if(x<0||x>=4||y<0||y>m)return ;
if(vis[x][y]||e[x][y]!='*')return ;
cnt++;//统计每个联通块中的数量
vis[x][y]=1;
for(int i=-1;i<=1;i++)
for(int j=-1;j<=1;j++)
dfs(x+i,y+j);
}
int main()
{
vector<int>v1;
cin>>m;
for(int i=0;i<4;i++)
cin>>e[i];
for(int i=0;i<4;i++)
{
for(int j=0;j<m;j++)
if(e[i][j]=='*'&&!vis[i][j])
{
cnt=0;
dfs(i,j);
v1.push_back(cnt);
}else vis[i][j]=1;
}
cout<<v1.size();//总共多少个联通块
return 0;
} 进阶
模拟战役:https://ac.nowcoder.com/acm/problem/14698
P1002 过河卒:https://www.luogu.com.cn/problem/P1002
//该题搜索40分,dp可拿满分,dp需要注意的是预处理,第一行第一列当存在有马那么其后都应该置位0for(int i=0;i<n;i++)
{
f[i]=1;
for(int j=0;j<i;j++)
{
if(a[j]<=a[i])
f[i]=max(f[i],f[j]+1);
}
}题意:有正有负的一个序列,求最大的子序和(保证子串连续)
/*1:动态规划
设f[i]以i结尾的连续的最大子序和,则f[i]=(f[i-1]+a[i],a[i]),最后再求一下最大的f[i](for(int i=0;i<n;i++)res=max(res,f[i]))
2:贪心
我们发现当sum<=0这种情况,他一定不会在继续为后边的序列贡献答案,所以枚举该序列,for(int i=0;i<n;i++){if(sum<=0)sum=0;sum+=a[i];res=max(res,sum)}
*///用分治法解决,将序列分成两部分:左边最大和,右边最大和,最大和包含左边和右边
#include<iostream>
#include<cstdio>
#include<algorithm>
using namespace std;
const int N=1e7+5;
int a[N];
int f(int l,int r)
{
if(l==r)return a[l];//结束条件
int m=l+r>>1;
int ans=max(f(l,m),f(m+1,r));
int ll=0,rr=0,tmp=0;
for(int i=m;i>=1;i--)
{
tmp+=a[i];
ll=max(ll,tmp);
}
tmp=0;
for(int i=m+1;i<=r;i++)
{
tmp+=a[i];
rr=max(rr,tmp);
}
ans=max(ans,ll+rr);
return ans;
}
int main()
{
int n;
scanf("%d",&n);
for(int i=1;i<=n;i++)
scanf("%d",&a[i]);
printf("%d\n",f(1,n));
return 0;
}
//超时了 n件物品v容量的背包,第i件物品体积vi,价值wi,求将那些物品放入背包,使物品总体积不超过背包容量,且价值最大
原题链接:https://www.acwing.com/problem/content/2/
n=4,v=5
v[i] w[i]
1 2
2 4
3 4
4 5 - - [x] | 物品\体积 | 0 | 1 | 2 | 3 | 4 | 5 | | :-------: | ---- | ---- | ---- | ---- | ---- | ---- | | 0 | 0 | 0 | 0 | 0 | 0 | 0 | | 1 | 0 | 2 | 2 | 2 | 2 | 2 | | 2 | 0 | 2 | 4 | 6 | 6 | 6 | | 3 | 0 | 2 | 4 | 6 | 6 | 8 | | 4 | 0 | 2 | 4 | 6 | 6 | 8 |
/*
f[i][j]表示前i个物品容量不超过j时的最大价值
那么:对于第i件物品有两种选择
1:不选择第i件物品 f[i][j]=f[i-1][j]
2:选择第i件物品 f[i][j]=f[i-1][j-v[i]]+w[i],这里选择第i件物品本身就是容量j就要减去v[i](因为我们已经选择了它)
最后求的是f[n][m]
首先要做的初始化
1:对于f[0~n][0]=0,不管多少个物品,他的体积=0,那么价值始终是0
2:对于f[0][0~n]=0,不管体积多大,他始终是0个物品那么价值始终是0
*/
#include<iostream>
using namespace std;
const int maxn=1e3+5;
int f[maxn][maxn],n,m;//n个物品,m背包体积
int v[maxn],w[maxn];//v[i],w[i]第i个体积和价值
int main()
{
cin>>n>>m;
for(int i=1;i<=n;i++)
cin>>v[i]>>w[i];
for(int i=1;i<=n;i++)//枚举n个物品
{
for(int j=1;j<=m;j++)//枚举体积
{
f[i][j]=f[i-1][j];
if(j>=v[i])//这里是因为我们选择的第i件物品的体积必须<=j才能够选他
f[i][j]=max(f[i][j],f[i-1][j-v[i]]+w[i]);
}
}
cout<<f[n][m]<<endl;
return 0;
}
/*
*这里定义的是f[i][j]前i个物品体积不超过j时的最大价值,那么初始化条件应该是
f[i~n][0]=0,f[0][j~v]=0;
在二维dp的基础上,我们可以降低到一维dp,可以看到我们枚举的是n个物品,然后枚举v的体积,我们第二层循环每层的答案只与上一层有关,那么我们可以把第一位去掉,这里需要从后往前枚举体积v因为我们对答案的更新状态有两种,一种是不选很显然f[i][j]=f[i-1][j],转换成f[j]=f[j],没毛病,那么当选了第i个物品,f[i][j]=f[i-1][j-v[i]]+w[i],可以知道我们想要的答案是在上一层靠左边的,所以如果第二层循环从小到大枚举体积,会破坏掉对之后答案的贡献,只能从后往前枚举f[j]=f[j-v[i]]+w[i]
*/
#include<iostream>
#include<algorithm>
using namespace std;
const int N=1e3+5;
int f[N],v[N],w[N],n,V;
int main()
{
cin>>n>>V;
for(int i=1;i<=n;i++)cin>>v[i]>>w[i];
for(int i=1;i<=n;i++)
{
for(int j=V;j>=v[i];j--)
f[j]=max(f[j],f[j-v[i]]+w[i]);
}
cout<<f[V]<<"\n";
return 0;
}//上一种做法和这一种做法,定义状态不同,初始化条件不同。
/*接下来另一种定义
f[i][j]表示前i个物品容量恰为j时的最大价值
那么:对于第i件物品有两种选择
1:不选择第i件物品 f[i][j]=f[i-1][j]
2:选择第i件物品 f[i][j]=f[i-1][j-v[i]]+w[i],这里选择第i件物品本身就是容量j就要减去v[i](因为我们已经选择了它)
最后求的是max{f[n][0~v]}
初始化f[0][0]=0,和上边的有区别
*/
#include<iostream>
#include<algorithm>
using namespace std;
const int maxn=1e3+5;
int f[maxn][maxn],n,m;
int v[maxn],w[maxn];
int main()
{
cin>>n>>m;
for(int i=1;i<=n;i++)
cin>>v[i]>>w[i];
for(int i=1;i<=n;i++)
{
for(int j=0;j<=m;j++)
{
f[i][j]=f[i-1][j];
if(j>=v[i])
f[i][j]=max(f[i][j],f[i-1][j-v[i]]+w[i]);
}
}
int res=0;
for(int j=0;j<=m;j++)
res=max(res,f[n][j]);
cout<<res<<endl;
return 0;
}如果f[j]表示体积小于等于j的最大价值,那么f[]应该全部初始化成0;如果表示体积恰好是j的最大价值,那么f[]应该初始化成负无穷(除了f[0] = 0)。就是状态的定义方式,决定了状态的初始化方式。
那么为什么当表示体积小于等于j时的最大价值时,要初始化成0呢? 这里最好从原始状态来考虑:dp的边界是f[0] [j],表示一个物品都不选,体积不超过j的最大价值,那么“一件物品都不选”这个方案是合法的,它的价值是0,因此需要把f[0] [j]初始化成0。 当表示体积恰好等于j时的最大价值时,还是从定义出发,f[0] [j],表示一件物品都不选,体积恰好是j的最大价值,那么只有当j == 0时有合法方案,j等于其他值时没有合法方案,因此只有f[0] [0] = 0,其余f[0] [j] = -INF。
//进行优化变成一位数组
/*
f[i]表示体积<=i的最大价值
初始化:f[]全部=0
*/
#include<iostream>
#include<algorithm>
using namespace std;
const int N=1e3+5;
int f[N],v[N],w[N],n,m;
int main()
{
cin>>n>>m;
for(int i=1;i<=n;i++)cin>>v[i]>>w[i];
for(int i=1;i<=n;i++)
for(int j=m;j>=v[i];j--)
f[j]=max(f[j],f[j-v[i]]+w[i]);
cout<<f[m]<<endl;
return 0;
}#include<iostream>
using namespace std;
const int N=1010;
int f[N],v[N],w[N],n,m;
int main()
{
cin>>n>>m;
for(int i=1;i<=n;i++)cin>>v[i]>>w[i];
for(int i=1;i<=n;i++)
{
for(int j=v[i];j<=m;j++)
f[j]=max(f[j],f[j-v[i]]+w[i]);
}
cout<<f[m]<<endl;
return 0;
}紫书353详细讲到了,其实就是递归实现无根树到有根数的转换,pre[i]数组标记的是i的父亲,那么我们随便指定一个节点为根节点,并标记pre[i]=-1,说明它是根节点。其他递归实现。
题目:输入一个拥有N个结点的无根树的边,指点一个结点为根节点,把这棵树转化为一棵有根树,输出各个节点的父亲编号。n<=10^6。
#include<iostream>
#include<vector>
using namespace std;
const int maxn=1e6+5;
vector<int>e[maxn];
int n,root,pre[maxn];
void read_tree()//构造图
{
int u,v;
cin>>n;
for(int i=0;i<n-1;i++)//n个节点有n-1条边
{
cin>>u>>v;//构造无向图
e[u].push_back(v);
e[v].push_back(u);
}
}
void dfs(int u,int fa)//将无根树转换为有根数
{
int d=e[u].size();//寻找以u出发的边的个数
for(int i=0;i<d;i++)//枚举每条u出发边
{
int v=e[u][i];//u->v
if(v!=fa)//这是因为当存在枚举u-v中的v是u的父亲时,要结束,否则会无限循环
dfs(v,pre[v]=u);//递归v寻找v的儿子,同时标记v的父亲时u
}
}
int main()
{
read_tree();
cin>>root;
pre[root]=-1;
dfs(root,-1);
for(int i=0;i<n;i++)
cout<<i<<"fa is"<<pre[i]<<endl;
return 0;
}https://www.bilibili.com/video/BV1u7411p7V8?t=1538在国内 OI 界,你可能听说过的“SPFA”,就是 Bellman-Ford 算法的一种实现。(优化)
Bellman - ford算法是求含负权图的单源最短路径的一种算法,效率较差O(n*m),代码难度较小。其原理为连续进行松弛,在每次松弛时把每条边都更新一下,若在n-1次松弛后还能更新,则说明图中有负环,因此无法得出结果,否则就完成.
为什么是松弛n-1次?简单来说就是从源点到一个点的最短路最极限的一种情况的路径需要经过全部的点,也就是需要松弛v-1次,这样,我们执行v-1次就可以保证所有的点都松弛到最佳的情况,如果执行了v-1次后还能继续松弛,那就说明图中有负权环,无解.
//初始化
memset(dist,0x3f,sizeof(dist));
dist[1]=0//起点到起点距离为0//初始化dist[1]=0;其他inf
for(int i=1;i<=n-1;i++)
{
int flag=false;//优化(当内层循环一次也没进行过松弛操作可退出)
for(int j=0;j<m;j++)
if(dis[e[j].v]>dis[e[j].u]+e[j].w)//松弛操作
{
dis[e[j].v]=dis[e[j].u]+e[j].w
falg=true;
}
if(!flag)break;
} void Bellman_frod()
{
for(int i=1;i<n;i++)
{
int flag=false;//优化(当内层循环一次也没进行过松弛操作可退出)
for(int j=0;j<m;j++)
if(dis[e[j].v]>dis[e[j].u]+e[j].w)//松弛操作
{
dis[e[j].v]=dis[e[j].u]+e[j].w
falg=true;
}
if(!flag)break;
}
//判断是否是负权环(原理:上边松弛操作后就不可能在松弛了,如果还能进行松弛操作就说明存在负权环)
for(int i=0;i<m;i++)//m代表边的的数目
if(dis[e[j].v]>dis[e[j].u]+e[j].w)
return true;//存在负权环
return false;
}
//经典例题 洛谷:(P3385 【模板】负环)[传送们](https://www.luogu.com.cn/problem/P3385)
/*
//这道题最后一个数据卡了一下,原因是:最后1没有和其他节点相连
//解决办法:add修改一下(就是加法)
int addd(int a,int b)
{
if(a==inf||b==inf)return inf;
else
return a+b;
}
//待解决:还没彻底明白
*/单源最短路SPFA即 Shortest Path Faster Algorithm。
很多时候我们并不需要那么多无用的松弛操作。
很显然,只有上一次被松弛的结点,所连接的边,才有可能引起下一次的松弛操作。
那么我们用队列来维护“哪些结点可能会引起松弛操作”,就能只访问必要的边了。
SPFA是Bellman-ford的一种优化,用邻接表来存储图G。我们采取的方法是动态逼近法:设立一个先进先出的队列用来保存待优化的结点,优化时每次取出队首结点u,并且用u点当前的最短路径估计值对离开u点所指向的结点v进行松弛操作,如果v点的最短路径估计值有所调整,且v点不在当前的队列中,就将v点放入队尾。这样不断从队列中取出结点来进行松弛操作,直至队列空为止。该算法期望复杂度是O(ke),但是可以被特殊数据卡到O(nm)O(n**m),所以如果图中没有负权边时不建议使用该算法。
#include<iostream>
#include<queue>
#include<cstring>
using namespace std;
int u,v,w,s,dist[n+1],vis[n+1];//s起点,dist[i]存储第i个顶点离起点s的最短距离,vis[i]判断顶点i是否在队列中
struct edge{
int v,w,next;
}e[m+1];//存储每条边的信息
void add(int u,int v,int w)//链式前向星代替邻接表存图(相当于领接表)
{
cnt++;//cnt统计边的个数
e[cnt].v=v;
e[cnt].w=w;
e[cnt].next=head[u];
head[u]=cnt;
}
queue<int>q;
void spfa()
{
memset(dist,0x3f,sizeof(dist));
dist[s]=0;
q.push(s);
vis[s]=1;//s已经进入队列
int u,v;
while(!q.empty())
{
u=q.front();
vis[u]=0;//u已经出队列
q.pop();
for(int i=head[u];i;i=e[i].next)
{
v=e[i].v;
if(dist[v]>dist[u]+e[i].w)//松弛操作
{
dist[v]=dist[u]+e[i].w;
if(vis[v]==0)//没有进入队列并且进行了松弛操作加入队列
{
q.push(v);
vis[v]=1;//进入队列
}
}
}
}
}
int main()
{
cin>>n>>m>>s;//n个顶点,m条边,s起点
for(int i=0;i<m;i++)
{
cin>>u>>v>>w;
add(u,v,w);
}
spfa();
for(int i=1;i<=n;i++)//输出起点到i点的最短距离
cout<<dist[i]<<" ";
}该算法本质上的思想是贪心,它只适用于不含负权边的图.我们把点分成两类,一类是已经确定最短路径的点,称为"白点",另一类是未确定最短路径的点,称为"蓝点"。我们将初始点的dis设为0,其他点的dis设为无穷大,不断取出蓝点中距离最小的点对其他蓝点进行更新,然后将其改成白点。该算法的正确性是基于当所有边长都是非负数的时候,全局最小值不可能再被其他节点更新了,我们不断用当前全局最小值进行松弛可以保证正确性。
邻接表+堆优化
#include<iostream>
#include<queue>
#include<cstdio>
using namespace std;
const int maxn=2e5+5;
int n,m,s,cnt,head[maxn];
ll dis[maxn];
//int vis[maxn];//可以代替if(d!=dis[u])continue;
struct edge{
int v,w,next;
}e[maxn];
void add(int u,int v,int w)
{
cnt++;
e[cnt].v=v;
e[cnt].w=w;
e[cnt].next=head[u];
head[u]=cnt;
}
struct node{
int u;
ll dis;
bool operator<(const node&x)const{//重新定义<运算符
return dis>x.dis;
}
};
void dij()
{
pority_queue<node>pq;//优先队列每次弹出dis最小值
pq.push(node{s,0});
while(!pq.empty())
{
node t=pq.top();
pq.pop();
int u=t.u,d=t.dis;
if(d!=dis[u])continue;
// if(vis[u])continue
// vis[u]=1;//可以代替上边的操作
for(int i=head[u];i;i=e[i].next)
{
int v=e[i].v,w=e[i].w;
if(dis[v]>dis[u]+w)
dis[v]=dis[u]+w;
pq.push(node{v,dis[v]});
}
}
}
int main()
{
cin>>n>>m>>s;//n个顶点m条边s起点
for(int i=1;i<=m;i++)
{
cin>>a>>b>>c;//从a到b有一个路径为c的边
add(a,b,c);//有向图
}
for(int i=1;i<=n;i++)//初始化dis数组
dis[i]=1e9+5;
dis[s]=0;//起点0
dij();
for(int i=1;i<=n;i++)//输出起点s到各个顶点的距离
printf("%d ",dis[i]);
printf("\n");
reutrn 0;
}void init()
{
for(int i=1;i<=n;i++)
for(int j=1;j<=n;j++)
e[i][j]=inf;//对矩阵初始化,inf表示不存在边(i,j)
}
void dij()
{
memset(dis,inf,sizeof(dis));
dis[1]=0;
for(int i=1;i<=n;i++)
{
int maxx=inf,x=0;
for(int i=1;i<=n;i++)//找出最小的距离
if(!vis[i]&&dis[i]>m)maxx=dis[x=i];
vis[x]=1;//代表x已在最短路集合中
for(int y=1;y<=n;y++)
if(dis[y]>dis[x]+e[x][y])
dis[y]=dis[x]+e[x][y];
}
}Floyd是一种可以以n^3复杂度处理处图上任意点对最短距离的算法,它的实现原理也很直观,我们假设从i出发到j,只有两种情况,第一种是i,j间本来就有边,另一种是我们从i走到k,再从k走到j,Floyd就是枚举出所有的i,j,k,以三层循环不断更新所有点对的最短路
for(int k=0;k<n;k++)//中转节点
for(int i=0;i<n;i++)
for(int j=0;j<n;j++)
e[i][j]=min(e[i][j],e[i][k]+e[k][j]);for(int i=1;i<=n;i++)//n:n个节点
pre[i]=i;int find(int x)
{
if(x==pre[x])return x;
else
return pre[x]=find(pre[x]);//(含状态压缩)
}void merge(int x,int y)
{
int fx=find(x);
int fy=find(y);
if(fx!=fy)pre[fx]=fy;
}模板题传送门
试题 历届试题 合根植物传送门
思路:n行m列的植物,初始化节点,将k行的两个植物进行合并,最后遍历一遍查询多少个集合即可
P1536 村村通 传送门
思路:简单的并查集即可做,先将道路联通的合并起来也就是合并成集合,最后查找有多少个集合,ans-1即可
vector+结构体+队列(拓扑排序有向无环图)
const int maxn=1e5+5;
struct Edge{
int v,dis;
};
int topo[maxn];//存储结果
vector<Edge>G[maxn];
int indegree[maxn];//节点的入度数
//1表示存在拓扑序0表示有环
void input(int n,int m)
{
int u,v;
for(int i=0;i<m;i++)
{
cin>>u>>v;
e[u].push_back(v);
//e[v].push_back(u);//这里我构造了无向图,其实应该构造有向图的,之所以
//构造无向图也能通过的原因是:无向图在遍历某节点的边时,会重新再把入度为0
//的也判断一下,但是此时 indegree[i]已经=0再自减的话变成-1,还是不能选择,因此不会出错
indegree[v]++;
}
}
bool topo_sort()
{
int cnt=0;
queue<int>q;
for(int i=0;i<n;i++)
{
if(in_degree[i]==0)
q.push(i);
}
while(!q.empty())
{
int u=q.front();
q.pop();
topo[cnt++]=u;
for(int i=0;i<G[u].size();i++)
{
int v=G[u][i].v;
if(--in_degree[v]==0)
q.push(v);
}
}
return cnt==n;//判断有没有环的存在,返回1说明cnt确实和n相等,没有环的存在,否则有环
}#include<iostream>
#include<vector>
#include<queue>
#include<algorithm>
using namespace std;
const int maxn=1e4+5;
vector<int>ee[maxn];
int ru[maxn],mx[maxn],n,ti[maxn],ans;
void topo_sort()
{
queue<int>p;//该队列维护的是入度为0的顶点
for(int i=1;i<=n;i++)//寻找入度为0的顶点
if(ru[i]==0)
{
p.push(i);//找到入度为0的顶点
mx[i]=ti[i];//存储该顶点完成工作所需的时间
}
//mx[u]=ti[u];
while(!p.empty())
{
int u=p.front();
p.pop();
for(int i=0;i<ee[u].size();i++)
{
int v=ee[u][i];
if(--ru[v]==0)
{
p.push(v);
}
mx[v]=max(mx[v],mx[u]+ti[v]);
}
}
for(int i=1;i<=n;i++)//循环每个任务是因为有可能在n个任务重有一个任务完成时间最长,但是他是独自的一个连通分量
ans=max(mx[i],ans);
}
int main()
{
int a,b,c;
cin>>n;
for(int i=1;i<=n;i++)
{
cin>>a>>b>>c;//a工作序号,b工作时间,c表示以a为终点的顶点
ti[a]=b;//记录工作序号下的工作时间
while(c!=0)//c!=0说明他有前驱即入度不为0
{
ee[c].push_back(a);//存储以c为起始点连接其他的顶点
cin>>c;
ru[a]++;//入度++
}
}
topo_sort();
cout<<ans<<endl;
return 0;
}模板:拓扑排序
可达性统计,拓扑排序的变种问题,具体思路就是拓扑排序一下,反向遍历每个排好序的节点,反向相加,需要用到bitset位集合的数据结构
/*
这份代码可以完美诠释cin cout与scanf,printf相比到底有多慢,详见下图
*/
#include<iostream>
#include<bitset>
#include<vector>
#include<queue>
#include<cstdio>
using namespace std;
const int N=3e4+5;
bitset<N>f[N];//第一维是节点数,第二维是二进制集合
vector<int>e[N];//存储边的集合,作用跟邻接表(也可用邻接表存边)一样,邻接矩阵根本存不下...
int n,m,indu[N],topo[N],cnt;//indu[]入度的个数,topo[]存储拓扑排序的结果,cnt节点个数
void input()
{
int u,v;
for(int i=0;i<m;i++)
{
//cin>>u>>v;
scanf("%d%d",&u,&v);
e[u].push_back(v);//构建有向图,拓扑排序有向无环图,易错点
indu[v]++;
}
}
void sort_tupo()
{
queue<int>q;
for(int i=1;i<=n;i++)//先找到入度0的节点
if(indu[i]==0)
q.push(i);
while(!q.empty())
{
int u=q.front();
topo[cnt++]=u;
q.pop();
for(int i=0;i<e[u].size();i++)
{
int v=e[u][i];
if(--indu[v]==0)
q.push(v);
}
}
}
int main()
{
//cin>>n>>m;
scanf("%d%d",&n,&m);
input();
sort_tupo();
for(int i=cnt-1;i>=0;i--)//将节点从后往前遍历
{
int u=topo[i];
f[u][u]=1;
for(int j=0;j<e[u].size();j++)
{
int v=e[u][j];
f[u]|=f[v];//进行或运算其实就是进行并集
}
}
for(int i=1;i<=n;i++)
printf("%d\n",f[i].count());//输出其中1的个数
//cout<<f[i].count()<<endl;
return 0;
} 
Minimal Spanning Tree
描述
把所有边排序,依次考查每条边。若u已经和v连通,那么将(u,v)加入生成树后会产生环,不可加入。否则将(u,v)加入生成树中一定是最优的。
!怎么加入(u,v)前判断他是不是联通的?并查集
const int maxn=1e5+5;//一般边数大于顶点数
int pre[maxn];
struct edge{
int from,to,dist;
bool operator<(const edge&rhs)const{
return dist<rhs.dist;
}
}e[maxn<<1];
int find(int x)
{
return x==pre[x]?x:pre[x]=find(pre[x]);
}
int main(){
//input();
sort(e,e+maxn<<1);
for(int i=1;i<=n;i++)
pre[i]=i;
int sum=0,cnt=0;
for(int i=1;i<=m;i++)//m表示边数
{
if(find(e[i].from)==find(e[i].to))
{
continue;
}
pre[find(e[i].from)]=find(e[i].to);//边不连通加入
sum+=e[i].dist;//将边加入最小生成树
if(++cnt==n-1)//优化也就是说当加入n-1条边结束
break;
}
cout<<sum<<endl;
return 0;
}
例题
村庄建设 传送门:http://oj.hzjingma.com/contest/problem?id=129&pid=8&_pjax=%23p0
来源:蓝桥杯模拟赛
#include<iostream>
#include<algorithm>
#include<cmath>
using namespace std;
const int maxn=2e6;
struct edge{//存边
int from,to;
double dist;
bool operator<(const edge&other){//重载小于运算符
return dist<other.dist;
}
}e[maxn];
int pre[maxn],x[maxn],y[maxn],h[maxn],cnt,n;
void add(int u,int v,double w)
{
cnt++;
e[cnt].from=u;
e[cnt].to=v;
e[cnt].dist=w;
}
void input()
{
cin>>n;
for(int i=1;i<=n;i++)
cin>>x[i]>>y[i]>>h[i];
int xx,yy,hh;
double dist;
for(int i=1;i<=n;i++)//计算两个村庄之间的费用
{
for(int j=i+1;j<=n;j++)
{
xx=abs(x[i]-x[j]);
yy=abs(y[i]-y[j]);
hh=abs(h[i]-h[j]);
dist=sqrt(xx*xx+yy*yy)+hh*hh;
add(i,j,dist);//将边存入
}
}
}
int find(int x)//并查集
{
return x==pre[x]?x:pre[x]=find(pre[x]);
}
int main()
{
double sum=0.0;
int count=0;
input();
sort(e+1,e+cnt+1);//按照边从小到大排序
// for(int i=1;i<=cnt;i++)
// printf("%d %d %lf\n",e[i].from,e[i].to,e[i].dist);
for(int i=1;i<=n;i++)//初始化并查集
pre[i]=i;
for(int i=1;i<=cnt;i++)//对cnt条边进行查找
{
if(find(pre[e[i].from])==find(e[i].to))//两点已经连通,就不把边加入最小生成树
continue;
pre[find(e[i].from)]=find(e[i].to);//加入最小生成树并且把它放到集合里
sum+=e[i].dist;
if(++count==cnt-1)break;//优化一下
}
sum=round(sum*100);//四舍五入
sum/=100;
printf("%0.2lf\n",sum);
return 0;
} 
将序列分成左右两个区间,以一个元素为中间元素,一般是以第一个定为中间元素(但会被卡,高效的话定义中间元素(l+r>>1)为中间元素),然后从左往右找比中间元素大的,从右往左找比中间元素小的,两者交换位置。之后以中间元素为分割线左边都是比mid小的,右边都是比mid大的,实际上这已经实现了部分排序(只不过左右内部边没有排序)之后递归实现左右部分都排序,直到L>=R退出
//快排模板很多,这个模板基本最优了,不会被卡。
#include<iostream>
#include<cstdio>
using namespace std;
const int maxn=1e5+5;
int a[maxn],n;
void quick_sort(int l,int r)
{
if(l>=r)return a[l];//结束
int i=l-1,j=n+1,t=a[l+r>>1];//这里+1是因为下边的j--(不会越界)l+r>>1优化一下
while(i<j)
{
do i++;while(a[i]<t);
do j--;while(a[j]>t);
if(i<j)swap(a[i],a[j]);
}
quick_sort(l,j);//j一定是在左区域的最后一个,所以j+1是右区域
quick_sort(j+1,r);
}
int main()
{
cin>>n;
for(int i=0;i<n;i++)
scanf("%d",&a[i]);
quick_sort(0,n-1);
for(int i=0;i<n;i++)
printf("%d ",a[i]);
return 0;
}
//快速排序的版本很多,一不小心很容易出错!求第k小数?
//快排模板很多,这个模板基本最优了,不会被卡。
#include<iostream>
#include<cstdio>
using namespace std;
const int maxn=1e5+5;
int a[maxn];
void quick_sort(int l,int r,int k)
{
if(l>=r)return ;//结束
int i=l-1,r=n+1,t=a[l+r>>1];//这里+1是因为下边的j--(不会越界)l+r>>1优化一下
while(i<j)
{
do i++;while(a[i]<t);
do j--;while(a[j]>t);
if(i<j)swap(a[i],a[j]);
}
if(j-l+1>=k)
return quick_sort(l,j,k);//j一定是在左区域的最后一个,所以j+1是右区域
if(j-l+1<k)
return quick_sort(j+1,r,k-(i-l+1));
}
int main()
{
int n,k;
for(int i=0;i<n;i++)
scanf("%d",&a[i]);
int ans= quick_sort(0,n-1,k);
cout<<ans<<endl;
return 0;
}
//快速排序的版本很多,一不小心很容易出错!//求第k小数方法2
/*
nth_element(a,a+k-1,a+n)求第k小数,从0开始
头文件#include<algorithm>
功能排序第k小数其他还是无需状态,在数据特别多的时候效率很高
*///yxc模板
void merge_sort(int q[], int l, int r)
{
if (l >= r) return;
int mid = l + r >> 1;
merge_sort(q, l, mid);
merge_sort(q, mid + 1, r);
int k = 0, i = l, j = mid + 1;
while (i <= mid && j <= r)
if (q[i] <= q[j]) tmp[k ++ ] = q[i ++ ];//那里的=号在求逆序对时必须写上
else tmp[k ++ ] = q[j ++ ];
while (i <= mid) tmp[k ++ ] = q[i ++ ];
while (j <= r) tmp[k ++ ] = q[j ++ ];
for (i = l, j = 0; i <= r; i ++, j ++ ) q[i] = tmp[j];
}
作者:yxc
链接:https://www.acwing.com/blog/content/277/
来源:AcWing求逆序对数?
#include<iostream>
using namespace std;
typedef long long ll;
const int maxn=1000005;
ll a[maxn];
ll Merge_sort(int l,int r)
{
if(l>=r)return 0;
int m=l+r>>1;
ll res=0;
res+=Merge_sort(l,m);
res+=Merge_sort(m+1,r);
int i=l,j=m+1,cnt=0;
ll t[r-l+1];
while(i<=m&&j<=r){
if(a[i]<=a[j])//其实=应该放在前边,不能放在后边
t[cnt++]=a[i++];
else{
res+=m-i+1;//此处是寻找逆序对个数,因为当if不满足说明后边所有的数都是比i到m这大的个数并且满组了逆序对,所以m-i+1
t[cnt++]=a[j++];
}
}
while(i<=m)t[cnt++]=a[i++];
while(j<=r)t[cnt++]=a[j++];
for(int i=l,j=0;j<cnt;i++,j++)
a[i]=t[j];
return res;
}
int main()
{
int n;
cin>>n;
for(int i=0;i<n;i++)
cin>>a[i];
cout<<Merge_sort(0,n-1)<<endl;
return 0;
}//[力扣的88.合并两个有序数组(更好理解归并排序)]https://leetcode-cn.com/problems/merge-sorted-array/特兰数是组合数学中的一种著名数列,通常用如下通项式表示(为了不与组合数C冲突,本文用f表示卡特兰数
给定N个节点,能构成Catalan(N)种形状不同的二叉树。
思路:直接用公式计算f(n)即可
证明过程:传送门
//求解Cn^m
typedef long long ll;
ll C(int n,int m)
{
ll ans=1;
if(m<n-m)m=n-m;//小优化,避免溢出
for(int i=m+1;i<=n;i++)
ans*=i;
for(int i=1;i<=n-m;i++)
ans/=i;
return ans;
}
//对于Cn^m=n!/((n-m!)*m!),第一个循环做到的是ans=n!/m!,m应该越大越好,避免溢出,第二个循环做的是ans/(n-m)!//递归法,很容易溢出 n=21,m=1就会溢出,不过是中间溢出超过int类型了
ll factorial(int n)
{
ll ans=1;
for(int i=1;i<=n;i++)
ans*=i;
return ans;
}
ll C(int n,int m)
{
return factorial(n)/(factorial(m)*factorial(n-m))
}int read()
{
int s = 0, f = 1;//s存值,f判断正负
char ch = getchar();
while(!isdigit(ch)) {
if(ch == '-') f = -1;
ch = getchar();
}
while(isdigit(ch)) {
s = s * 10 + ch - '0';
ch = getchar();
}
return s * f;
}
//
int read()
{
int x=0,f=1;
char ch=getchar();
while(ch<'0'||ch>'9')
{
if(ch=='-')
f=-1;
ch=getchar();
}
while(ch>='0' && ch<='9')
x=x*10+ch-'0',ch=getchar();
return x*f;
}#include<cassert>
using namespace std;
int main()
{
int a=5;
assert(a==5);
cout<<a<<endl;
return 0;
}
//assert作用其实就是当结果和我们断言不一样的时候回报错,帮助我们debugint main()
{
vector<int>arr;
arr.push_back(2);
arr.push_back(2);
arr.push_back(2);
arr.push_back(5);
arr.push_back(6);
int len=unique(arr.begin(),arr.end())-arr.begin();
assert(len==3);
for(int i=0;i<len;i++)
cout<<arr[i]<<" ";
cout<<len<<endl;
return 0;
}
//上述实现的就是在数组有序情况下可以删除数组重复项#include<algorithm>
using namespace std;
int read()
{
int s = 0, f = 1;
char ch = getchar();
while(!isdigit(ch)) {
if(ch == '-') f = -1;
ch = getchar();
}
while(isdigit(ch)) {
s = s * 10 + ch - '0';
ch = getchar();
}
return s * f;
}
int main()
{
int t,n,k;
scanf("%d",&t);
while(t--)
{
int n;
//scanf("%d%d",&n,&k);
n=read();
k=read();
for(int i=0;i<n;i++)
a[i]=read();
//scanf("%d",&a[i]);
nth_element(a,a+k-1,a+n);
printf("%d\n",a[k-1]);
}
return 0;
}
//__int128 16字节 long long 8字节
例题:快速幂
[](https://ac.nowcoder.com/acm/problem/23046)
这道题用__int128可以在爆long long 条件下不会产生溢出优先队列(priority_queue)#include
//定义:priority_queue<Type, Container, Functional>
//Type即数据类型,Container:容器类型,Functional:比较方式
//升序队列,小顶堆
priority_queue <int,vector<int>,greater<int> > q;
//降序队列,大顶堆
priority_queue <int,vector<int>,less<int> >q;
//默认是打大顶堆,降序排序
priority<int>q
//greater和less是std实现的两个仿函数(就是使一个类的使用看上去像一个函数。其实现就是类中实现一个operator(),这个类就有了类似函数的行为,就是一个仿函数类了)
q.top()//弹出第一个
//例如想要用vector的迭代器
vector<int>::iterator it;在字符串中查找字符
str.find(tt,index)
//返回tt在str字符串中第一次出现的位置,从index下标开始查找。没找到返回string::npos(-1),其中tt支持是string或者char *
str.find(tt,index,length)
//返回str在字符串中第一次出现的位置(从index开始查找,长度为length)。如果没找到就返回string::npos
str.find(c,index)
//返回字符ch在字符串中第一次出现的位置(从index开始查找)。如果没找到就返回string::npos 返回某个子字符串
T=str.substr(index,num)
//substr()返回本字符串的一个子串,从index开始,长num个字符,当不指定num时,默认直接返回从index开始后剩余的字符串string str;
str.erase(str.size()-k)//删除后k个字符串
str.erase(position,len)//删除从position位置起的len个长度
//例如1234567890
str.erase(5,3)//输出1234590
str.erase(position)//删除从position位置开始的后面所有元素
#include<iostream>
#include<string>
using namespace std;
int main()
{
string s=to_string(1)+to_string(2);
cout<<s<<"\n";
return 0;
}#include<utility>//老忘记他的头文件....
pair<T1, T2> p1;
//创建一个空的pair对象(使用默认构造),它的两个元素分别是T1和T2类型,采用值初始化。
pair<T1, T2> p1(v1, v2);
//创建一个pair对象,它的两个元素分别是T1和T2类型,其中first成员初始化为v1,second成员初始化为v2。
make_pair(v1, v2);
// 以v1和v2的值创建一个新的pair对象,其元素类型分别是v1和v2的类型。
p1 < p2;
// 两个pair对象间的小于运算,其定义遵循字典次序:如 p1.first < p2.first 或者 !(p2.first < p1.first) && (p1.second < p2.second) 则返回true。
p1 == p2;
// 如果两个对象的first和second依次相等,则这两个对象相等;该运算使用元素的==操作符。
p1.first;
// 返回对象p1中名为first的公有数据成员
p1.second;
// 返回对象p1中名为second的公有数据成员struct node{
int x,y;
node():x(),y(){}//无参构造
node(int x,int y):x(x),y(y){}//有参构造
};/*
求职题一般都是直接给类,函数式编程,本地测试如下:
*/
#include<bits/stdc++.h>
using namespace std;
class Solution {
public:
/**
*
* @param s string字符串
* @return string字符串
*/
string change(string s) {
// write code here
string s1,s2;
for(int i=0;i<s.size();i++)
{
if(s[i]=='a')
s2+='a';
else s1+=s[i];
}
return s1+s2;
}
}test;
int main()
{
cout<<test.change("");
return 0;
}
/*
注意:c++中类的成员方法中申请int类型内存空间不能超过1e6超过的话,不会报错,但是运行不出来结果,一般数据范围太大,需要定义在类的成员变量中
另外力扣评测的话,自己在申请int类型的空间时,多组数据,需要初始化的话,建议换种思路,不要用memset(vis,0,sizeof(vis)),因为评测机貌似不会执行这个过程。
*/